
Decision Support technologies evolved considerably in the past few years and they are about to reach a plateau and enter a phase where they will mature. The next significant growth of those technologies will be achieved by merging the distinct decision support technologies as we know them today (OLAP/ROLAP, Ad Hoc Query/Report Writing and Data Mining) into an end-to-end solution for data consumers ranging from business analysts to senior executives.
OLAP analysis
The acronym OLAP stands for On-Line Analytical Processing and refers to interactive data analysis on a computer as opposed to browsing through stacks of thick printed reports.
Currently, OLAP tools are typically used by a small community, mainly composed of managers and executives, to analyze trends in their organization for general management and strategic planning. These users want to know whether: revenues and expenses are increasing or decreasing on a monthly or quarterly basis compared to the previous years; Are we meeting our objectives (Budget vs. Actual)?; Which regions or product lines have the most significant impact on our business?
The concept of OLAP first appeared in the late 1970s but it started gaining recognition in the 1980s with the appearance of the first significant OLAP applications, called EIS (Executive Information System). An EIS system was a programmed interface that allowed managers to easily track some key business indicators. The fact that the EIS application was programmed meant that the layout or presentation was rather static, users were able to navigate through the OLAP structure and data in a pre-determined fashion. EIS applications were host-based and only used desktop PCs as clients. The early 1990s marked the birth of desktop and client/server OLAP products. As OLAP applications evolved, they became more sophisticated, flexible and interactive.
Multidimensionality
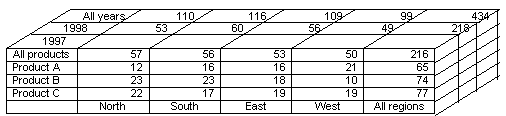
A concept that is inseparable from OLAP is multidimensional analysis meaning that the OLAP structure can model multiple factors or variables. The business world is composed of a vast array of dimensions such as time (years, months), geography (countries, regions), business partners (customers, suppliers) and the products or services they exchange, see Table 1. A significant benefit from multidimensionality is that by storing the information in a structure similar to the business environment, it simplifies the process of business analysis by recreating a world that users can understand, which is generally not true of a relational database schema.
Navigating through the OLAP structure
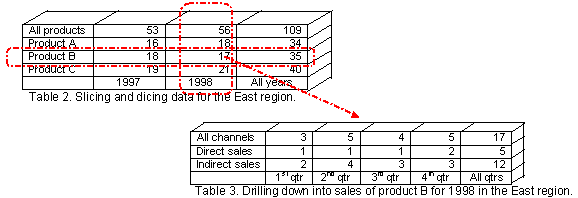
Even though the OLAP structure is multidimensional, our computer screens limit us to presentations in two dimensions. To navigate through the OLAP structure with the tools that we have, we slice and dice through the data. Basically, what this means is since we cannot visualize all the data at once, we will extract a piece of it from the structure, analyze that part and if that chunk is still too large to comprehend, dice it into even smaller pieces, see Table 2. Once we have isolated an area of interest, for instance Table 2 shows that sales of product B are declining in the East region, we want to extend our analysis and retrieve additional information pertaining to this focal point, this is called "drilling down" (see Table 3).
Performance
One of the goals of OLAP technology, is to achieve speed-of-thought response times. To achieve great performance, the OLAP structure is typically predefined and the information it contains is usually summarized (aggregated) data. When an analyst wants to know if sales have been increasing regularly over the past year, the total sales for each month is the only data required, not every order placed by customers.
In order to achieve optimal response times, the transactions are pre-summarized and stored in a multidimensional database (MDDB) that uses special indexing algorithms optimized for this type of structure. In an MDDB, data is accessed by specifying the coordinates of the slice of data or cell we want to retrieve. Typically, no data manipulation or computation is required because the necessary processing is done when the data is transferred from the transaction system(s) to the MDDB.
To improve performance in a relational database (RDBMS), you can also create tables containing pre-summarized data, called "aggregate sets". Unfortunately, the relational database structure was developed to work in a two-dimensional space, so if you want to achieve response times comparable to those of OLAP, you will run into "database explosion".
An aggregate set comparable to the structure illustrated in Table 1 would require the creation of seven (7) tables, see Table 4, in order to retrieve every value without any manipulation or aggregation when the user requests the data. This may appear like overkill in this simple example, but if the database receives a million transactions a day across 5 000 products for 20 000 customers (think of a large supermarket chain) and you want to measure this on a monthly basis over 2 years, then it becomes a real issue. The number of tables required to cover every scenario of aggregation is obtained by the formula 2n - 1. A structure with five (5) dimensions would then require 25 - 1 = 31 summary tables.
The aggregate set approach greatly increases the level of difficulty required to maintain the application as well as the size of the database. Because of those issues, when aggregate sets are implemented, a compromise has to be made between the aggregate tables where performance is most critical and the complexity of the structure.
|
Categories of OLAP
OLAP tools can be grouped into four categories mainly differentiated by the database engine.
DOLAP (Desktop OLAP) : These tools take data from a relational database or the results of a query, and store it in a multidimensional structure called a hypercube, which resides on the user’s desktop PC. Once the hypercube is created, the PC can be disconnected from the data source and the users have everything they need locally to proceed with the data analysis. The main advantage of DOLAP is its simplicity to implement.
OLAP or MOLAP (Multidimensional OLAP) : This category refers to the traditional methodology of OLAP where data is extracted from multiple relational databases and heterogeneous data sources (ASCII files, spreadsheets, …) and incorporated into a multidimensional database. The greatest advantage of MOLAP is its performance, while on the other side the problem we face is scalability.
As we add dimensions to the database structure its complexity grows exponentially, which restricts the scope of OLAP analysis to management-level information. As a new dimension or a new dimensional element is added to the structure, the database has to be restructured and every total or sub-total stored in the MDDB has to be re-computed, which can be a costly process. As the MDDB gets closer to the detailed transaction-level, the structure becomes more volatile and you are essentially duplicating your data.
ROLAP (Relational OLAP) : This category of OLAP tools gives users a multidimensional view of the data which still resides in a relational database system (RDBMS). The advantages of this methodology is no data duplication and greater scalability. The multidimensional structure is virtual and based on information contained in the database (metadata) which adds flexibility; as the data changes so does the multidimensional structure.
RDBMS are already used to store massive amounts of transactions and to implement gigantic data warehouses. Re-using that infrastructure makes this category of OLAP tools scalable both in structure and in depth (detailed data). Unfortunately, the main problem with ROLAP is performance. Even though they present data in a multidimensional format, the medium used to store the information is an RDBMS which was not conceived for this type of analysis. In practice, to work around this limitation, people create aggregate tables which bring up the issues previously mentioned and take away the advantage of "no data duplication".
HOLAP (Hybrid OLAP) : The latest generation of OLAP tools provides the integration of multidimensional databases with relational databases. In the HOLAP structure, static high-level aggregate data is stored in an MDDB while structurally volatile and detailed information remains in the RDBMS. As requests are made by the users, the OLAP tool will transparently retrieve the information from the appropriate location.
Typically, dimensions such as years, months, regions, product lines do not change very often and are stored in the MDDB while more operational dimensions like products, customers and order number would be accessed directly from the RDBMS. This gives the users a completely scalable OLAP solution while keeping the MDDB easy to maintain. The performance is generally acceptable even as you access operational information because when the users end up requesting low-level data from the RDBMS, a lot of filtering (slicing and dicing) has already been done.
This provides the best of both worlds and the keyword with hybrid OLAP is integration. Applications that let the data reside in the RDBMS and create an hypercube when data is requested or that store an MDDB (structure and data) in a relational database should not be considered hybrid OLAP solutions. They only offer you a combination of the technologies not an integration.
Ad Hoc query tools and report writers
Ad Hoc query tools and report writers are used by a wider community, mainly composed of business analysts, for localized management and problem solving focusing on specific areas.
Typically, predefined or standard queries are executed on a regular basis to confirm that the organization is meeting management’s expectations and measure the various activities involved in day-to-day operations. Ad hoc requests can also be submitted as special questions arise.
Query tools provide data access and extract the information from the database. Report writers handle the presentation of those results. Most products now offer an integrated interface that allows you to build the queries and format the presentation.
Managed Query Environment (MQE)
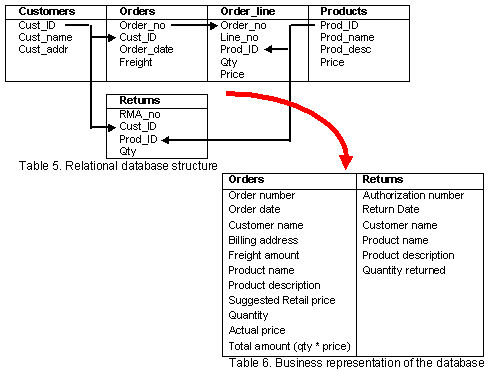
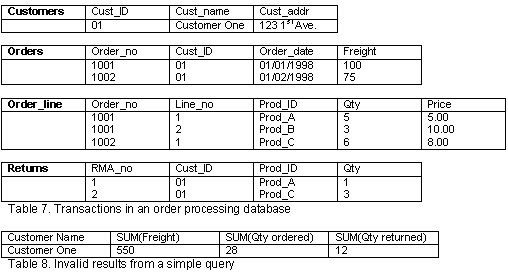
The current generation of query tools also provides a managed query environment (MQE) where the complexity of the database structure (Table 5) is hidden from the users and transposed into a business representation (Table 6).
SQL as a query language
One major hurdle still remains preventing IT departments from rolling out query tools to the entire user community, the language used to communicate with the database, SQL (Structured Query Language). Just like the English language, SQL has both a syntactic and a semantic layer. Every query tool needs to generate SQL statements that are syntactically correct otherwise the database will reply with an error message. A simple example using the structure described in Table 5, would be if we asked for a list of products that were returned, showing the quantity and the date when they were returned. Since the return date is not part of our database, it would reply with an error message saying that the request is invalid. Unfortunately, there are very few products that also make sure that their statements are semantically correct. The problem in this case is that the database will understand the request and return results that can be invalid in a "business sense".
Let’s build a simple example that will illustrate two of those semantic problems within one single query. We want to build a query that will show us the total amount spent for freight and the total quantity of items ordered vs. returned for each of our customers using the data contained in Table 7. As unbelievable as it may seem, the vast majority of query tools currently available on the market will return the results displayed in Table 8.
The reason for those incorrect results is that those tools do not understand semantics and request information that cannot be properly interpreted in one SQL statement. The relationships between the tables in this example, illustrated by the arrows in Table 5 can be interpreted as the five following sentences: "A customer can place many orders", "An order can contain multiple lines of detail, one for each product ordered", "A customer can obtain many return authorizations", "A product can be ordered many times" and "A product can be returned many times".
The two semantic rules violated in this example could be described as "you cannot aggregate two levels of details" and "you cannot request data from a Many-to-One-to-Many relationship". The first rule is broken when we ask for "the total amount spent for freight and the total quantity of items ordered" while the second is ignored by asking for "the total quantity of items ordered vs. returned". Ignoring the latter, generates what is referred to as a Cartesian product and is probably the most frequent cause of the query that brings your network "to its knees". In our example, with a very small data set, you can see that the results returned for the quantity ordered were double what they should have been and the quantity returned was tripled. If we increased our data set to one million order lines and five thousand returns, the database would actually generate 5 billions records before returning results which as you can imagine would be totally disproportionate.
Simple business questions can be complex queries
The SQL language and the business language are different which means that some simple business problems or questions can be difficult to translate in a SQL statement. Users will rapidly run into roadblocks as they try to use those tools to answer questions such as :
Compare the revenues of this year vs. last year - to achieve this, the query tool will need to generate two statements, one for this year’s revenues and another for last year, then combine the results from both queries. This is called a multi-pass SQL.
What percent of customers have orders with more than 3 products? - This will require a multi-pass SQL as well as a correlated sub-query.
While many tools can now generate queries that will satisfy the first example, probably less than a handful of products will be able to help your users with the second one.
Data mining
Data mining is part of a process called knowledge discovery where the goal is to better understand the organization’s data in order to resolve business problems or capitalize on opportunities. Some of the steps in the knowledge discovery process are defining the problems or opportunities you want to address, collecting, cleaning, preparing and analyzing the data and most importantly, interpreting the results. Data mining is the step where specific algorithms are applied to historical data in order to identify hidden patterns and relationships (correlations).
The origins of data mining date back to the 1960s and statistical analysis. Some of the algorithms used in those days were correlation, regression, chi-square and cross tabulation. In the 1980s, the field of artificial intelligence emerged and brought additional algorithms or techniques used to analyze data such as fuzzy logic, heuristic reasoning and neural networks.
OLAP and query tools vs. data mining
OLAP and query tools help you manage your organization by letting managers and business analysts keep an eye on trends and visually identify hot spots in the data that require their attention or answer day-to-day business questions as they arise. Those tools help them answer questions like "What were the sales of product X last year and how were they distributed?". Data mining tools help answer questions like "Why did sales of product A decline after September?"
A major distinction between OLAP/Query tools and data mining is in the task distribution. With OLAP/Query tools the user navigates through the data but with data mining, the tools analyze the data and provide feedback to the users.
Applications of data mining
With the current proliferation of data marts and data warehouses, data mining is just starting to emerge. The impact of data warehousing on this field is that data mining tools work on historical data and as the amount and variety of data increase, the chances of accurately predicting the outcome of new transactions will also increase. This is true of any analysis based on statistical functions or algorithms. As the use of data mining increases, numerous business applications will surface such as the following :
Customer relationship management. Analysis of customer attrition (churn) is of great interest for most organizations who need to understand why their customers are turning to their competitors in order to increase customer retention and attract others from their competitors by understanding the characteristics of those customers who are ready to change provider.
Marketing. A common application of data mining is to improve profitability of direct-mail campaigns by focusing on the audience most likely to response and generate more significant revenues while at the same time reducing costs by limiting the scope of the campaign. Another popular application is market basket analysis which shows the relationships among items purchased at the same time.
Finance. Data mining is commonly used for credit risk analysis and fraud detection.
Healthcare. Applications can be used for tracking the effectiveness of medical procedures or detect side effects of various drug combinations.
Categories of data mining
Data mining tools create analytical models that are descriptive, predictive or both. Descriptive models help answer questions such as "Why did sales of product A decline last month?". Predictive models are used for forecasting and help answer questions like "How much revenue will be generated by the new product C?".
Data mining tools can model a number of different problems. The most common of these are :
Classification and regression - the most widely spread category of data mining is used to create models that predict class membership (classification) or a value (regression). Some business applications are to predict customer behavior or store profitability, detect potentially fraudulent transactions or identify candidates for medical procedures.
There are several techniques used for classification and regression including decision trees, neural networks, Naïve-Bayes and nearest neighbor. Classification and regression generate predictive models.
To illustrate the various techniques used, let’s build a simple example. A travel agency offers 2 vacation destinations : Disneyland and Europe. The agency’s database contains information regarding the customer name, the price paid, the number of children, the duration of the vacation and the destination selected. The destination is called the dependent variable which suggests that the selection will be based on the other columns, which are defined as independent variables implying that the price paid does not affect the number of children nor the duration of the vacation (in real life, we can all agree that they can all be related but for this example let’s pretend they are independent).
Some tools will strictly work with categorical data meaning that the variables must contain discrete values instead of continuous. For instance, the price paid for the vacation could be anywhere from $100 to $10 000. To convert those values into categorical data we apply a process called bracketing or binning. Basically, we group the values into a limited set such as moderate for a price between $100 and $3000 and high for the other values. For this example, we will also group the children information into no (0) and yes (1 or more) and the duration will be short (1 week or less) or long (more than 1 week). Table 9 illustrates the data from previous transactions.
| Customer | Price | Children | Duration | Destination |
| Michael | High | No | Long | Europe |
| Robert | Moderate | Yes | Short | Disneyland |
| Mary | Moderate | No | Short | Europe |
| Peter | High | Yes | Long | Europe |
| Charles | High | No | Long | Europe |
| Kate | Moderate | Yes | Short | Disneyland |
Decision trees. A decision tree generates a model that is both predictive and descriptive. The data mining algorithm will analyze the data, generate a model presented in the form of a tree structure (this process is called tree induction) and display the output either graphically (see figure 1) or textually (see figure 2). The resulting output is very easy to understand and makes this technique very popular.
To predict the destination selected by a potential new customer (Bill) who wants to go on a long vacation with no children and has a high budget, simply follow the decision tree and you will predict that this customer will more than likely select the trip to Europe. On a larger scale, if the travel agency is planning to open a new office they can look at demographics information and organize an advertising campaign that will be adapted to the new prospect base.
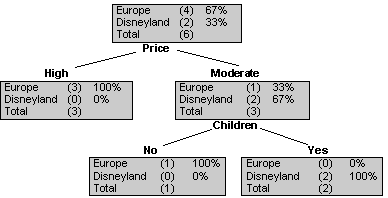
Figure 1. Decision tree for the travel agency.
|
IF Price is High OR (Price is Moderate AND Children = No) THEN Destination = Europe IF Price is Moderate AND Children = Yes THEN Destination = Disneyland |
Neural Networks. A neural network generates a model that is strictly predictive. They are very efficient and fast enough to be used for predictions in real time. The reasoning behind the output of a neural network is very hard to comprehend and is often referred to as a "black box" technology which causes other techniques to be preferred to it. A neural network is basically a mathematical function that computes an output by applying the function to the input variables. A neural network only works with numerical values, so the first thing we will do is translate the transaction values into numbers. To simplify the example we will use 0 and 1 as numbers but any number would do, the need is to adapt the data type not the values. Let’s translate our values as 0 for moderate price, no children, short duration, Disneyland destination and 1 for high price, yes to children, long duration and Europe (see Table 10).
| Customer | Price | Children | Duration | Destination |
| Michael | 1 | 0 | 1 | 1 |
| Robert | 0 | 1 | 0 | 0 |
| Mary | 0 | 0 | 0 | 1 |
| Peter | 1 | 1 | 1 | 1 |
| Charles | 1 | 0 | 1 | 1 |
| Kate | 0 | 1 | 0 | 0 |
A neural network is composed of nodes and the number of input, hidden and output nodes is called the network topology. In our example, the input nodes are the independent variables (price, children, duration) and the output node is the destination. Intermediate results leading to the final output are stored in what is defined as hidden nodes because the user is only aware of the input and the output of the neural network. The algorithm computes a weighted sum based on the input variables at each node and returns an output. The weight applied to each input and the number of hidden nodes are established by separate algorithms. For our example, we will label the input nodes as A (price), B (children) and C (duration), use 2 hidden nodes (labeled D and E) and label the output node as F (destination), see Figure 3.
We will use the following mathematical functions to compute the output of nodes D,E and F :
D = IF (A - 3B + 2C) >= 0 THEN 1 ELSE 0
E = IF (-2A + 4B - C) >= 0 THEN 1 ELSE 0
F = IF (4D - 3E) >= 0 THEN 1 ELSE 0
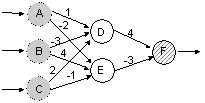
If we process the potential customer Bill, who (A) has a high budget (1), (B) wants to go on a vacation with no children (0) and (C) for a long time (1) through the neural network, we will obtain the following prediction :
D = 1 - 3*0 + 2*1 = 3 >= 0 -> 1
E = -2*1 + 4*0 - 1 = -3 < 0 -> 0
F = 4*1 - 3*0 = 4 >= 0 -> 1
The output (F = 1) of the neural network for Bill is that we predict he will go to Europe.
Naïve-Bayes. The Naïve-Bayes technique works on categorical values and generates a model that is both predictive and descriptive which can be used for classification only. It is based on a Bayes’ Theorem and computes probabilities that are used to make predictions. In theory, all the independent variables must be statistically independent for the prediction to be accurate, since this assumption is usually not true in practice, the data mining technique inherited the adjective "naïve" and was called Naïve-Bayes. The application of Bayes’ Theorem is to predict the probability of the dependent variable (destination) based on the conditional probabilities of the independent variables. We will then compute a score for each possible value of the dependent variable and select the highest score to be the predicted value.
The first step is to evaluate the conditional probabilities for each independent variable as well as the prior probabilities for each destination, see Table 11. For instance, the conditional probability that a vacation to Europe has a high price is 0.75 because 3 out of the 4 trips to Europe had a high price and the prior probability that Europe is the destination is 0.67 (4 out of 6 trips).
| Independent variable | Value |
Count Europe |
Probabilities Europe |
Count Disneyland |
Probabilities Disneyland |
| Price | High | 3 | 0.75 | 0 | 0 |
| Moderate | 1 | 0.25 | 2 | 1.00 | |
| Children | No | 3 | 0.75 | 0 | 0 |
| Yes | 1 | 0.25 | 2 | 1.00 | |
| Duration | Long | 3 | 0.75 | 0 | 0 |
| Short | 1 | 0.25 | 2 | 1.00 | |
| Total by destination | 4 | 0.67 | 2 | 0.33 | |
The second step is to assign a score to each combination of independent variables and predict the destination, see Table 12. To obtain each score we multiply the conditional probabilities of each independent variable by the prior probability. For instance, Michael obtains a score of (0.75 * 0.75 * 0.75 * 0.67 = 0.283) for Europe and (0 * 0 * 0 * 0.330= 0) for Disneyland.
| Customer | Price | Children | Duration |
Actual destination |
Score Europe |
Score Disneyland |
Predicted destination |
| Michael | High | No | Long | Europe | 0.283 | 0 | Europe |
| Robert | Moderate | Yes | Short | Disneyland | 0.010 | 0.330 | Disneyland |
| Mary | Moderate | No | Short | Europe | 0.031 | 0 | Europe |
| Peter | High | Yes | Long | Europe | 0.094 | 0 | Europe |
| Charles | High | No | Long | Europe | 0.283 | 0 | Europe |
| Kate | Moderate | Yes | Short | Disneyland | 0.010 | 0.330 | Disneyland |
Nearest neighbor. The nearest neighbor technique is usually referred to as k-nearest neighbor (or k-NN) and generates a predictive model used for classification. This algorithm makes a prediction for a new entry based on a specified number (k) of similar cases (neighbors).
The nearest neighbors are determined by defining a distance measure that will be applied to the historical data set in comparison with the new transaction. This definition is strictly arbitrary, for instance, we could determine that for a vacation destination selection, the difference between a duration of 1 or 2 weeks is greater (has more impact on the choice) that the difference between 2 or 6 weeks. In that case, we could define the distance between 2 and 6 weeks as 1 unit and the distance between 1 and 2 weeks as 2 units even though it appears mathematically illogical.
In our travel agency example, since every variable can take 2 values, we will define the measure as 0 if the values are identical and 1 if they are different; and select k = 3. Table 13 illustrates the distance between each transaction in the historical data set. For instance, the distance between Robert and Mary is 1 [0 (Moderate = Moderate) + 1 (Yes ¹ No) + 0 (Short = Short)].
| Michael | Robert | Mary | Peter | Charles | Kate | |
| Michael | 0 | 3 | 2 | 1 | 0 | 3 |
| Robert | 3 | 0 | 1 | 2 | 3 | 0 |
| Mary | 2 | 1 | 0 | 3 | 2 | 1 |
| Peter | 1 | 2 | 3 | 0 | 1 | 2 |
| Charles | 0 | 3 | 2 | 1 | 0 | 3 |
| Kate | 3 | 0 | 1 | 2 | 3 | 0 |
To validate the model, let’s process the historical data through the model (algorithm). Table 14 gives the prediction for each historical transaction and achieves an accuracy rate of 83% because 5 out of the 6 predictions were correct. To improve the accuracy, we could either increase k or modify the distance measure.
| Customer | Price | Children | Duration |
Actual destination |
k-Nearest neighbors |
Predicted destination k=3 |
| Michael | High | No | Long | Europe | Michael,Charles,Peter | Europe |
| Robert | Moderate | Yes | Short | Disneyland | Robert,Kate,Mary | Disneyland |
| Mary | Moderate | No | Short | Europe | Mary,Robert,Kate |
|
| Peter | High | Yes | Long | Europe | Peter,Michael,Charles | Europe |
| Charles | High | No | Long | Europe | Michael,Charles,Peter | Europe |
| Kate | Moderate | Yes | Short | Disneyland | Robert,Kate,Mary | Disneyland |
Association and sequencing (often called market basket analysis) - this category of data mining is used to understand the relationships between events that occurred simultaneously (association) or consecutively (sequencing). The first popular application of this category was to understand customer behavior or purchasing trends (market basket analysis) for marketing purposes and has evolved into other areas such as finance and medicine. Association and sequencing generate descriptive models.
Association tools analyze the data and generate observations (rules) such as "When customers buy meat, they also buy red wine 60% of the time" or "When customers open a checking account, they also open a savings account 35% of the time".
While association considers simultaneous events, sequencing also takes into account subsequent transactions. For instance, a sequencing observation could be that 80% of the patients who take medication X develop disorder Y within 6 months.
Some products generate text rules while others display results in a compact tabular form.
If we take another look at our travel agency example and display additional information regarding options purchased as part of the vacation package, see Table 15, we could derive the following observations or rules : "100% of the people who took the hotel reservations also rented a car" and "50% of the people who rented a car also chose the local tours".
| Customer | Hotel reservations | Car rental | Local tours |
| Michael | Yes | Yes | No |
| Robert | Yes | Yes | Yes |
| Mary | No | Yes | Yes |
| Peter | No | No | Yes |
| Charles | Yes | Yes | No |
| Kate | No | No | No |
Those rules can be broken into 2 components, the antecedent (left-hand side) like "people who took the hotel reservations" and the consequent (right-hand side) like "also rented a car". Generally, since real life applications are more complex that this example and are composed of many variables, each component of the rules can contain multiple elements.
Rules have two basic measures called support (or prevalence) and confidence (or predictability). Support measures how often elements occur in the same transaction as a percentage of total and confidence measures the dependency of one element versus another. To evaluate the impact of a rule, we add another measure called lift which is expressed either as the difference or the ratio between the confidence of the rule and the expected confidence. The expected confidence is the percentage of occurrence for the consequent (right-hand side) of the rule. For instance, the expected confidence for the rule "when people take the hotel they also rent a car" is 66.67% (people took the car rental option in 4 transactions out of 6).
| Antecedent | Consequent |
Expected confidence (%) |
Confidence (%) |
Lift ratio |
Support (%) |
| Hotel reservations | Car rental | 66.67 | 100.00 | 1.50 | 50.00 |
| Car rental | Hotel reservations | 50.00 | 100.00 | 2.00 | 50.00 |
| Hotel reservations | Local tours | 50.00 | 33.33 | 0.67 | 16.67 |
| Local tours | Hotel reservations | 50.00 | 33.33 | 0.67 | 16.67 |
| Car rental | Local tours | 50.00 | 50.00 | 1.00 | 33.33 |
| Local tours | Car rental | 66.67 | 66.67 | 1.00 | 33.33 |
|
Hotel reservations and car rental |
Local tours | 50.00 | 33.33 | 0.67 | 16.67 |
|
Hotel reservations and local tours |
Car rental | 66.67 | 100.00 | 1.50 | 16.67 |
|
Car rental and local tours |
Hotel reservations | 50.00 | 50.00 | 1.00 | 16.67 |
| Hotel reservations |
Car rental and local tours |
33.33 | 33.33 | 1.00 | 16.67 |
| Car rental |
Hotel reservations and local tours |
16.67 | 25.00 | 1.50 | 16.67 |
| Local tours |
Hotel reservations and car rental |
50.00 | 33.33 | 0.67 | 16.67 |
In first rule (see Table 16), the confidence of 100% denotes the fact that every time customers take hotel reservations, they also rent a car and the support of 50% represents the fact that people select both options half the time.
In the second rule (see Table 9), "when people rent car, they also take hotel reservations", the lift ratio of 2.00 means that customers who rent cars are twice as likely to reserve an hotel than customers who do not rent cars. A lift ratio smaller than 1 is sometimes referred to as negative lift. For instance, in the third rule, the negative lift ratio (0.67) implies that a customer who makes a hotel reservation is less likely to take the local tours than a customer who does not make a hotel reservation.
Users of this technique, generally want to concentrate on the rules with the highest and lowest lift ratios accompanied by an acceptable support level. When the support level is very low, it means that the event happens rarely and if the enterprise tries to capitalize on these events, the impact of the measures taken will likely be less significant than if the enterprise acted on an event with a similar lift ratio but a very high support.
Moving towards an end-to-end decision support solution
The synergy between those distinct technologies will come from two key concepts : integration and standardization. This will be achieved through mergers and partnerships that are developing rapidly throughout the industry. With the proliferation of data warehousing initiatives, decision support products are becoming an important part of a suite of tools implemented along with the data warehouse or data mart.
Standardization
Common metadata : OLAP, query and data mining tools all need some form of metadata (information about the data structure they interact with) and this is also true of data warehouses, data marts. Each of these technologies looks at the world in its own fashion. Those mergers and partnerships will allow those various products to share the metadata information through the development of standards. An example of this is Informatica’s Metadata Exchange (MX) architecture which employs an API to exchange metadata between its data mart repository and various OLAP and query products.
Common language : Microsoft’s Universal Data Access (UDA) initiative includes OLE DB as the interface to data and will more than likely become the de facto standard used to interact with SQL (by encompassing ODBC) and non-SQL data sources. Another element of UDA is ActiveX Data Objects (ADO) which provide data access components optimized for Web applications and visual programming environments (Visual Basic, C++ or Java).
RDBMS vendors also have various Java integration projects currently in the works (triggers, stored procedures, storing Java objects, JDBC or even writing the DB server in Java). You can already see some of this in products such as IBM’s DB2 Universal Server, Oracle Lite 3.0 and Sybase Adaptive Server Anywhere.
Integration
Performance, flexibility and ease of use will come from the integration of those technologies at various levels. Query tools and report writers are generally already merged and hybrid OLAP is reducing the gap between MOLAP and ROLAP. To improve performance, you can anticipate that some OLAP and data mining functionality will be integrated within the kernel of relational database engines as database are already extending the core offerings. Some examples of this are Microsoft who will provide an OLAP engine called Plato within its next release of MS SQL Server, Informix and its Metacube product, Oracle and Oracle Express, Sybase whose ROLAP adventure gave birth to WhiteLight Systems Inc. and a recent partnership between IBM and Arbor Software. Red Brick provided its RISQL extensions and is now offering a data mining product (Data Miner) as part of its Red Brick Warehouse.
Distribution
As those technologies get pushed behind the scenes (server-based) and are accessed through common interfaces (metadata and languages), their distribution will be simplified through a more unified interface. This will help to promote new ways of interacting with the information such as groupware and webcasting.