 |

|
Introduction The expression "data rich, information poor" rings true today more than ever in most organizations, both big and small. The concept of "Business Intelligence", as it is known, addresses this paradox in a number of ways. Business intelligence, as shown in Figure 1, can be grouped into two general areas ľ Front end and Back end. On the Front end three categories of tools exist - Query/Reporting, Data Mining, and OLAP. A closer observation of these indicates that they can be further sub-divided. Query/Reporting applications are generally categorized into either "Standard" Query or Managed Query Environment (MQE). Data Mining components are generally thought of as being Classification and regression, Association and Sequencing, Clustering, or Data Visualization tools. Finally, OLAP is divided up into Multidimensional, Relational, Desktop, and Hybrid. There are also two components that make up the Back end. These are the Data Warehouse / Data Mart and Data Extraction / Cleansing tools. The Business Intelligence market is one of the most dynamic markets today. International Data Corporation (IDC) predicts that the analytic applications marketplace will grow to $2.6 billion from $800 million in 1997. In the case of business intelligence applications and services, IBM foresees growth to $70 billion Finally, the OLAP market itself is expected to grow to $1.5 billion in 2001. As can be seen from the above forecasts, the business intelligence market is potentially very lucrative. Therefore, it is imperative that the dynamics of the market as well as the various offerings from different vendors within this marketplace are understood. OLAP tools are categorized into three generic classifications; ROLAP or Relational OLAP, Multidimensional OLAP or MOLAP, and Hybrid OLAP or HOLAP. The distinction amongst these is somewhat convoluted. Each possesses its advantages and has its niche in an enterprise seeking a business intelligence solution. This paper analyzes the strengths and weaknesses of each OLAP tool. Finally, the conclusion briefly summarizes and compares each solution and examines the possible future direction of the OLAP market. The role of OLAP in the overall Business Intelligence solution of an organization is the focus of this paper. Discussed are issues such as different flavors of OLAP, accessibility and integration, and OLAPĺ s importance relative the other Business Intelligence (henceforth referred to as BI ľ read ĹBĺ,ĺIĺ) components. |
|
|
|
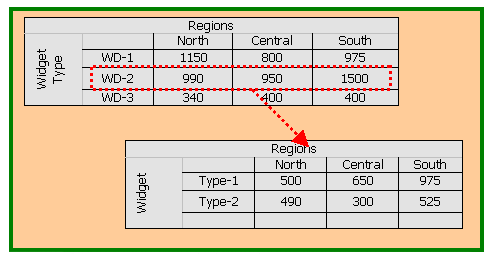
OLAP Technology The term OLAP, or On-line Analytical Processing, was coined in 1993 in a paper written by DR. E.F. Codd, S.B. Codd and C.T. Salley entitled "Providing OLAP (On-Line Analytical Processing) to User-Analysts: An IT Mandate". Contained within this paper are the rules outlining the requirements of an OLAP tool. However, discretion should be used when applying them generically against all OLAP applications. Analysts and the academic community perceive this work as being somewhat biased to multi-dimensional OLAP because it was sponsored by Arbor Software, a MOLAP vendor. Interestingly, Arbor recently announced the integration of some ROLAP functionality into its MOLAP engine. These rules are briefly discussed in the following section. For a complete discussion, please refer to the above-mentioned document. A common misconception amongst the user community is that OLAP tools perform the same tasks as Ad-hoc Query/Reporting tools. This is not so however. Both tools address different requirements. A Query / Reporting tool is designed to access data relationally and with a degree of production reporting in mind. Conversely, an OLAP tool accesses data multi-dimensionally. This allows for multi-dimensional navigation through the data, which is more appropriate and efficient for data analysis. The user or business analyst navigates through the multi-dimensional model by drilling into the data, either up, down or across. This simply means viewing data at different levels of aggregation. A variety of different terms are used when referring to these quantifiable values which are being measured. They are more commonly referred to as Metrics or KPIs ( Key Performance Indicators ). These are then viewed in terms of their Dimensions which are the qualitative attributes of the Metrics or KPIs. The composites of a Dimension are Elements. For example, supposing that I wish to study my Widget sales across my organization in order to determine where I am most and least profitable. Furthermore, assume that there are eight plants spread out in 3 regions. These plants each produce three separate product lines, each with 2 types of Widgets. In order to derive meaningful information from this data, I now need to compare the different aggregate values. As a manager, I can then use this information to make strategic decisions. In this case SALES is the metric or KPI, WIDGETS TYPES and REGIONS are the dimensions. Finally, the PHYSICAL WIDGETS and PLANTS are the ELEMENTS. Continuing the example using the above chart, the analyst or manager is interested in the Sales of product line WD-2. In order to obtain more detailed information, drills down on the row of data for Widget Category (WD-2). Similarly, the user could have chosen to perform analysis on a single cell as opposed to an entire row. In this case, Regions would have also been broken down ( in the same manner as Widget Categories ). The information needed to make a key decision is thus obtain simply by viewing the data in a top-down fashion, which is very intuitive and easily allows for Ĺmanagement by exception.' |
 |
|
Coddĺs Rules for Evaluating OLAP Tools An OLAP applicationĺ s Ĺraison dĺ etreĺ or purpose can be summarized, in laymenĺs terms, as ľ a method by which a user can analyze key business data quickly, easily and dynamically. Or, as defined by Dr. E.F. Codd, "OLAP (on-line analytical processing) is the name given to the dynamic enterprise analysis required to create, manipulate, animate, and synthesize information from exegetical, contemplative, and formulaic data analysis models (see the later section headed "Enterprise Data Models"). This includes the ability to discern new or unanticipated relationships between variables, the ability to identify the parameters necessary to handle large amounts of data, to create an unlimited number of dimensions (consolidation paths), and to specify cross-dimensional conditions and expressions." The authors (of the aforementioned paper) also describe three characteristics associated with OLAP. These characteristic are Dynamic Data Analysis, support for the Four Enterprise Models and conformance to Common Enterprise Data. Dynamic Data Analysis, simply put, is the analysis for "time series" data. It provides the analyst with an understanding of the changes that occur within the enterprise over time. |
 |
|
OLAP supports four distinct yet equally important enterprise data models; Categorical ľ data structure definition; Exegetical ľ storage of historical data in the structure; Contemplative ľ analysis of resulting possibilities if certain actions are taken, more commonly known as "what if" scenarios; and finally, Formulaic ľ the apparent correlation amongst seemingly unrelated data. Lastly, the third characteristic is that of Common Enterprise Data. OLAP is simply the Ĺanalysisĺ of existing Ĺtransactionsĺ collected via an OLTP system. There is no need to collect new data. |
|
|
|
As was described above, OLAP has certain characteristics. What, then, is needed to evaluate OLAP products in order to create a viable OLAP system? In the paragraphs that follow Coddĺ s 12 rules for evaluating OLAP tools are discussed (summarized in Table 1) and provide a foundation on which to build. A view that is conducive to cross-dimensional analysis and aggregation provides for a more intuitive analytical model. Therefore, the support for the multi-dimensional conceptual view of the data by the OLAP tool will ease in the "slicing and dicing" of the Ĺdata cubeĺ by the user-analyst. How the tool physically achieves this is discussed in the section entitled "Architectures of OLAP Tools". The user-analysts have no need to know, nor should they be concerned with the origin or source of the data used. Whether or not the source is heterogeneous or that an OLAP system is being used should be transparent to the end-user. Insofar as the user is concerned, they are utilizing the same types of interfaces so as to make the business decisions with which they were charged. Accessibility of the OLAP tool refers to its ability to map its own logical schema to that of the different enterprise data stores. It must also access the data from these heterogeneous data stores, carry out any required conversions in order to present users with a consistent view. The number of dimensions or their size (i.e. the number of elements comprising the dimension) should not affect reporting performance. Consistent reporting performance is key to providing the end-user with the results they are seeking. Should the user-analyst detect any significant lag time in obtaining the results to the desired query, an offsetting approach may be used. The user may request the information be presented in a manner that is insufficient instead of to what was actually sought. Because some, most or all the data is stored on a main frame or database server, Client-Server architecture is essential and therefore an OLAP tool should have the ability to function in this type of environment. The Generic Dimensionality rule states that all dimensions are created equally. Thus calculations and other manipulations, which are allowed in a certain dimension, are also legal in the context of others. The support of these generic operations makes it possible for the user to build dimensions with any attribute, which can then be used in any operation. An OLAP tool should be able to dynamically handle Sparseness of cells (i.e. those cells which do not contain a value as a percentage of all possible cells). The automatically provide the optimal mix between minimal memory and matrix usability. The OLAP tool should necessarily offer multi-user support. A strategic tool offers concurrent access while maintaining security and integrity. The rules that control data aggregation (i.e. data Ĺroll upĺ) throughout the hierarchy always apply consistently thus providing the basis for unrestricted cross-dimensional operations. The view used by the user-analyst should always contain all the necessary information for suitable maneuvering through the cube. Multiple interface operations should not be needed if the OLAP tool is intuitive in its manipulation of the data. Flexible reporting obliges the OLAP tool to provide whichever view of the data the user requests and exhibit it in any way required. The tool, in terms of the number of aggregate levels and the number of dimensions, should place no constraints. A Few more Rules Thus far we have seen the fundamental rules that define a good OLAP tool. The rapid evolution of OLAP coupled with escalating demand by an increasingly informed marketplace, however, makes it necessary to expand the guidelines of this definition to include a few more points. Openness through support of standard APIĺs is a must. As well, the tool should provide full access to enterprise data in some capacity. Finally, an OLAP tool should conform to the enterprise as opposed to the enterprise conforming to it. These points are discussed later in the paper. Moving forward, the key thing to remember about OLAP is that it is but ONE part of a data warehousing implementation, albeit significant. To understand how its integration is made possible, OLAP technology itself needs to be examined and explained. In the sections that follow, the different types of OLAP are examined; fore each has its place in the BI solution In general terms.
Architectures of OLAP Tools Multidimensional OLAP (MOLAP) Multi-Dimensional OLAP is characterized by the physical creation of a Multi-Dimensional Database (MDB). Unlike a traditional DBMSĺ whose design is based on a relational model, an MDBĺs structure is optimized for analysis. Stored multi-dimensionally in the MDB are all possible aggregates for each business KPI. The MDB consists of one or many matrices commonly referred to as hyper (or data)ĹCube(s)ĺ. Programmatically, a Ĺcubeĺ is nothing more than an array in which data is physically stored and retrieved using some algorithm. It is important to note at this point that each MDB has its proprietary format for storing data, though some may be Ĺopenĺ via APIs such as Microsoftĺs OLE DB for OLAP, OLAP Councilĺs API, or some other API. An MDB which stores all possible Key Performance Indicators, dimensions and elements across multiple matrices ( cubes ) is known as a Multi-Matrix MDB. These are typically implemented by associating each KPI (and its corresponding dimensions) with a single cube. The advantage with this model over an MDB which is designed using a single hyper cube is that virtually no physical limitation is placed on size of the MDB, although performance is best if its total physical size is kept under 5 to 10 GB. Furthermore, because there is no limit as to the MDBĺs size, there is also no limit as to the number of dimensions an indicator may have associated with it. Although the depth of the data being loaded into the MDB needs to be managed very carefully so as to prevent the cube(s) from exploding to unmanageable sizes. Clearly, there are definite benefits and drawbacks to carrying out analysis using an MDB. Cases where building an MDB is advantageous may be when no departmental data mart exists and/or sub-second query response time is not only desirable but a requirement. Also, an MDB can be designed and built relatively quickly and easily despite the source dataĺ s origin. Whether the aggregate values stored in the MDB are derived from a single data source or from disparate data sources, ultimately the outcome is the same since the MDB is an independent storage mechanism from the production DBMS. The extracted data from the DBMS is manipulated, cleansed and loaded into hyper cubes. The implication of having the raw data derived from disparate sources simply implies that multiple data loads must be run each loading period, one for each of the sources. While having the ability to easily load data from disparate data sources is certainly of great benefit, the loading process itself can be somewhat cumbersome. Consider the scenario where an MDB is being constructed with data obtained from a relational data warehouse or data mart. In this case 2 loads, of which both must comply with the organizationĺs business rules, are in fact being performed. First a data load that populates the data warehouse or data mart which extracts data from the DBMS is executed, followed by a second load that populates the MDB cubes with data extracted from this data warehouse or mart. In some cases this Ĺdouble loadĺ may prove beneficial, however. For example, if there is a need by analysts to view data Ĺoff lineĺ. Reason dictates that an OLAP tool that is intended to be used Ĺon lineĺ should have the ability to make use of data that is already in its refined state. Nonetheless, extracting data directly from the OLTP system in order to create a departmental MDB is certainly expedient. An enterprise seeking departmental MDBs, however, may potentially be faced with a problematic situation. MOLAP applications, for the most part, are fairly easily implemented. Hence, a department may choose to deploy an application with minimal or no input from the IT department. Herein lies the problem. This makes for an implementation with three possible obstacles. The application may not necessarily be correctly designed ( technically ). In addition, corporate considerations such as compatibility amongst the tools chosen by various departments as well as their ability to scale, both, may well have been overlooked. Certainly if sub-second query response time is required by the analyst, then MOLAP is by far the best choice. An MDBĺs ability to provide results instantaneously stems from its inherent characteristic of pre-calculating all possible aggregates or totals. As a result, only a single I/O is required in order to satisfy any query ( provided that its solution is obtainable from within the MDB ). For the more technically inclined, these results are retrieved with the use of indices and hashing algorithms. If the data required is not in the MDB, most MOLAP vendors provide analysts with the capability of retrieving data directly the DBMS. However, the process is quite impractical and requires SQL knowledge. Because of this as well as for the purpose of this discussion, MOLAP is considered to have no access to the data source. However, in the case where a question can be answered within the MDB the instantaneous results come at a premium. The predefined structure of the MDB is fairly rigid and inflexible. This is so because, if a dimension requires some type of modification, the entire cube will need restructuring. Furthermore, additions are exponential. Meaning that adding a single element will grow the cube exponentially based on the number of dimensions affected. The restructuring process itself may be measured in terms of minutes, hours or even, days. The physical space a cube occupies is determined by its ability to handle sparsity ( the point at which dimensions intersect where there is no value available ). In addition, a MOLAP application, because of its static nature handles time series analysis somewhat more awkwardly than its ROLAP counterpart. In part, this is due to its constrained size. If, for example, one would want to enter all fields that would typically be found in the ĹTime Dimensionĺ of a star schema ( year, month, day, quarter, fiscal quarter, fiscal year, event, day of week, etců) the cube size would explode to an unmanageable size. Finally, the time it takes to develop a MOLAP application is very short. A developer designs the application based on business rules and requirements. The procedure is then to simply load data into the cubes. Make no mistake, however, this is a compilation intensive procedure. By contrast, a relational application must adapt to the relational model, which can sometimes be awkward itself. In summary, the idea behind an MDB is to pre-load aggregate data for quick retrieval. In doing so, the analyst sacrifices flexibility. This sacrifice is gauged in terms of cube restructuring. Consider an example where a direct sales organization whose hierarchy is continuously evolving. Essentially, a MOLAP cube would need to be modified each time the hierarchy changed. This is probably not a desirable situation and an application that would be better suited for a ROLAP tool. Relational OLAP (ROLAP) As described in the previous section (MOLAP Described), it is necessary for a MOLAP tool to create a separate, proprietary storage mechanism in order to carry out OLAP analysis. Conversely, a ROLAP tool allows the analyst to view data contained within an RDBMS or data warehouse multi-dimensionally. Certainly ROLAPĺs key characteristics are Ĺreal-timeĺ data access and a dynamic, logical structure. Essentially, an analyst may sacrifice some degree of performance in favor of these benefits. A common misconception by consumers in the Business Intelligence market is Ĺthat data must be stored multi-dimensionally in order for it to be viewed multi-dimensionallyĺ. This is simply not so, though no contrary argument would be made by a MOLAP vendor. In a ROLAP environment, data in an RDBMS is viewed multi-dimensionally through the use of SQL ( Structured Query Language ). Do all vendors of ROLAP, then, not provide the same basic product? The distinction amongst ROLAP vendors, in this regard, is chiefly the degree of optimization for particular systems. Although there is an ANSI standard for SQL, SQL-92, DBMS vendorsĺ implementation and degree of compliance for this standard varies. Different systems employ different optimization mechanisms in order to enhance performance. A True Relational OLAP tool generates the appropriate optimized SQL depending upon the particular DBMS that is being used. At this point, one may have the misconception that in order to use a relational OLAP tool, the end user or analyst must necessarily be knowledgeable in SQL. This is frankly not so. The ROLAP engine is designed to construct optimized SQL based on criteria set by the user in a GUI, point-and-click client interface. Furthermore, developers of the ROLAP system are also do not require SQL knowledge. In a ROLAP environment, the possible lack of SQL knowledge does not impede the userĺs analytical capability. Moreover, the user has the ability to drill-down and analyze data at its finest level of granularity. Because the ROLAP engine is connected directly to the database or data warehouse, it provides unlimited dimensionality, providing unlimited slicing and dicing of the data. This means that a metric or KPI can have any number of dimensions (and elements) associated with it. By extension, this dynamic dimensionality is perfectly suited for time series analysis.
Additionally, there may be the erroneous perception that the client software actually treats and processes the data, thereby generating large amounts of network traffic. In actuality, it is the DBMS server that bears the work load and rightly so, as its processing power is orders of magnitude greater than that of the clientĺs. The physical exchange of information over the network is then merely the SQL request that is transferred from the client to the server and the result set back from the server to the client. A ROLAP tool places no constraint on the particular type of database schema that is used. Though in the interest of performance tuning these may be modified somewhat, all relational concepts such as many-to-many relationships, aggregate and partition sets, snowflake and star schemas, normalized and denormalized fact tables and multiple fact tables are all supported directly. An interesting paradigm here is, though the seemingly logical next step, very few ROLAP tools make full use of the databaseĺs metadata. The term metadata here is used in its broad definition to include primary keys, foreign keys, cardinality, business rules, etc. which pertain directly to the database.
One of the limiting factors of ROLAP is necessarily its power in terms of statistical analysis. A purely ROLAP tool that is fully dependant on SQL will experience difficulty in performing these types of calculations whereas one using MOLAP, because of its static nature, is more adept in performing these calculations. A True ROLAP tool has the capability of getting around this limitation. With such a tool, it is possible to obtain a result set using SQL and temporarily store these results where the desired statistical functions can subsequently be applied. Access to the entire scope of the data warehouse may yield an application that is richer in terms of functionality. The apparent compromise being that a more complicated setup is likely to be required for a ROLAP versus an MDB implementation. Furthermore, directly working against the DBMS allows for the ability to leverage existing database security, resulting in a single point of administration. Moreover, with this type of architecture the user is implicitly working in client/server mode. Hybrid OLAP (HOLAP) HOLAP is an interesting paradox. It, as of yet, has no clear definition in the marketplace. A wide range of vendors claim to have a HOLAP solution, yet no two vendors agree on its implementation. Theoretically, Hybrid-OLAP is a marriage of MOLAP and ROLAP technologies. Its intent is to take advantage of each architectureĺs strengths while omitting their weaknesses. Basically, the idea is to provide the fastest possible data retrieval times while allowing continued access to granular data. However, there are some important considerations to bear in mind when evaluating this type of architecture as a viable technology. For instance, although the concept ĹBest of both worldsĺ seems, on the surface, like a viable premise. The infamous quote " you have to take the good with the bad" should not be forgotten. In terms of HOLAP technology, this means that yes, there is the possibility of using the only the best features that make MOLAP and ROLAP technologies desirable. The problem lies in that there are intrinsic drawbacks for each technology. HOLAP, at its most rudimentary level, stores high level aggregate data and/or the most often used data in a MDB while the granular detail is left in the in the RDBMS but is yet still accessible. Furthermore, the possibility of joining the MDB to the DBMS exists. This differs quite significantly from the traditional MOLAP approach of providing access to the DBMS by allowing the analysts to code their own SQL requests. From a ROLAP perspective, the data that is stored in the multi-dimensional cube is static and thereby against its traditional philosophy. Key to HOLAP is the manner in which the MOLAP and ROLAP architectures are brought together. The degree of this integration is the determining factor in having a truly hybrid product. With a hybrid model, the labor invested in the DBMS should necessarily be leveraged and not duplicated. Furthermore, a HOLAP tool should be able to leverage heterogeneous data sources. Achieving this requires that certain criteria be met. Fundamentally, utilization of meta data must be the core criteria of a truly hybrid tool. It is inevitably required in order to provide seamless integration between the MDB and the RDBMS. Conceptually, one may consider that the MDB cubes replace certain aggregate and partition sets ( or tables ) that are inserted within the data warehouse architecture in order to enhance performance. This type of optimization technique is typical of a ROLAP implementation. The advantage of using multi-dimensional cubes versus aggregate tables is that they provide a more efficient means of aggregate storage that do aggregate/ partition tables. This is not to say that it is not necessary for the tool to support aggregate as well as partition sets. These can still be used for requests that are issued against the data warehouse. Likewise, the HOLAP tool should support many-to-many relationships via the use of relationship tables. In short, the hybrid tool should support the same type of optimization functionality found in ROLAP for queries that hit directly against the database. Using the meta data, critical measures ( metrics, KPIs ) as well as dimensions are derived from the relational database. Likewise all hierarchies are also derived from the database design. In the event that the desired level of aggregation does not exist in the relational database, it is then possible to add it fairly easily, provided that it is in the MDB portion of the architecture.
In Conclusion By virtue of its nature, a ROLAP application is much more scalable than a MOLAP application. In addition, it places no restrictions as to the number of elements that can be associated with a metric. Conversely, a multi-dimensional tool cannot support comfortably more that ten or so dimensions. Furthermore, the number of elements contained within a dimension is far less than that in a relational tool. However, the great benefit that MOLAP brings is very fast access speeds and the ability to work offline. Recall that in a MOLAP application it is not possible to obtain in its most granular form because of its cube size restriction. Both MOLAP and ROLAP are proven technologies in their particular niche. The issue then becomes the ultimate goal of the enterprise. If the goal is to access a large amount of data in a dynamic environment with a very scalable tool, then ROLAP is the best choice. On the other hand, if the goal is to deploy a relatively small scale application, yielding fast data access times and which can be developed quickly with little or no input from the IT department, a MOLAP tool is then a better choice. The manner in which MOLAP handles time is somewhat awkward. Therefore, if time series analysis is an intricate part of the business analysis process, a ROLAP tool would better serve a user. This is, once again, due to the physical size restrictions of the MOLAP data cube. Clearly each architecture, MOLAP and ROLAP possesses their distinct advantages. Although HOLAP attempts to leverage these advantages, it also brings along with it some of the overhead associated with each technology. In the case of MDBs, it is still necessary to load and maintain the cubes as well as contend with their physical limits. Similarly to relational-OLAP, the hybrid tool must still optimize the SQL it generates in order to enhance query performance. Additionally further DBMS tweaking will likely be required. One of the key features of HOLAP is that it promises to provide access to the underlying database seamlessly. This should not be confused with the manner in which a MOLAP tool will query this same database. The former is much more flexible and dynamic than the latter. At this point in time the market is certainly saturated with different OLAP options that are, to say the lease, confusing. The consumer is likely to see a convergence of these technologies where most if not all vendors will offer their product in some form of HOLAP, although they may not refer to it as such. Additionally, the market itself will change significantly. There will likely be a significant reduction in the number of OLAP vendors providing product to a broad horizontal market. Rather, the market will realign itself along vertical markets. Vendors are likely provide solutions using their products, rather than the products themselves. The OLAP market is certainly maturing quickly. Product features of not so long ago have now become prerequisites in the purchasing process. The next few years will certainly prove to be an exiting time in this market segment.
Choosing the right OLAP tool for you Consider the following criteria when choosing an OLAP your OLAP solution;
|
