
PROCESS IMPROVEMENT FOR HIGH AVAILABILITY
ABSTRACT
The need for faster and better access to business information is expanding in proportion to the rapid deployment of Internet/Intranet capabilities, distributed computing environments and end-users' expectation of availability. IT organizations are balancing the need to add new technologies (such as NT) and assume an enterprise role within their organizations while providing quality service. In this type of environment, computing systems require maximum high availability for decision making, application availability and operations productivity.
There is a mistaken belief in the computer industry that high availability is simply a hardware or software product that can be purchased. High availability is not redundant components and quick failover or recovery. Although these technology components are helpful and usually necessary, additional investments in people, process and monitoring technology are also required. High availability cannot be purchased, it must be planned, designed, built, measured, and managed.
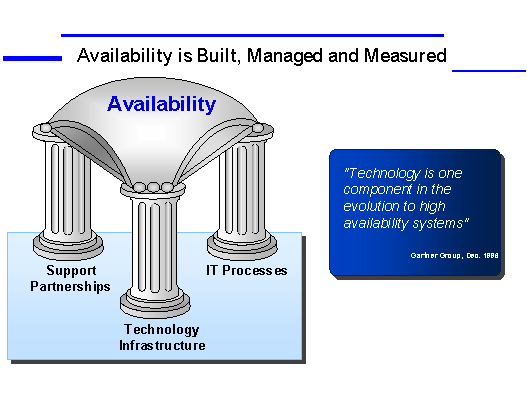
Availability is built on three pillars: technology infrastructure, support partnerships and IT processes. It is a continuous process of investment and quality improvement that meets the service levels required for essential business functions.
The Hewlett-Packard IT Service Management (ITSM) Reference Model can be used to identify processes within IT to target for these quality improvements. ITSM incorporates most of the IT Infrastructure Library (ITIL) best practices and terminology, which was developed in Europe and is propagating around the world. By improving and optimizing the processes within IT, companies will be able to provide mission critical applications with the required levels of availability.
What Is High Availability?
International Data Corporation defines high availability as follows: "A computer is considered to be highly available if, when failure occurs, data is not lost, and the system can recover in a reasonable amount of time." This simplistic definition can be used as a starting point for discussion. The definition of "a reasonable amount of time" can be different for each customer and for each application.
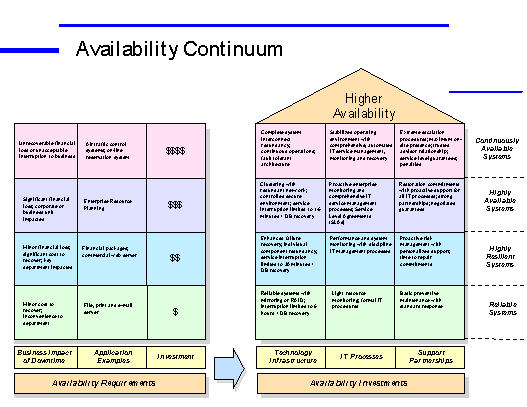
From a user perspective, she/he needs to have reasonable, continuous access to systems that respond fast enough to accomplish the business function for which the systems were designed. Both planned and unplanned downtime detracts from the availability of the application. Most users would request continuous application availability, but availability requirements must be business decisions. The more highly available a system needs to be, the more resources it takes and the more it costs. This added cost is only justified if there is sufficient value to the business.
Availability is a continuum, not a single state. It varies from reliable systems through highly available systems to fault tolerance and continuous availability. The following chart provides a framework for classifying applications into varying levels of availability.
Why Do You Need It?
High availability requirements are expanding in proportion to the rapid deployment of Internet/Intranet capabilities, distributed computing environments and end-users' expectation of availability. IT organizations are balancing the need to add new technologies (such as NT) and assume an enterprise role within their organizations while providing quality service. In this type of environment, computing systems require maximum high availability for decision making, application availability and operations productivity. In addition, IT organizations are asked to improve the level of service being provided, while their budgets remain flat or decrease.
More than 44% of the respondents in a study conducted by International Data Corporation (IDC) for Hewlett-Packard in June 1997 said their needs for high availability were growing. Factors driving this change are:
Current trends indicate that the number of mission critical applications will grow even faster as companies achieve true 24x7 global operations and invest more heavily in electronic commerce. Any downtime to these applications will become catastrophic. Dataquest estimates that more than one-third of all worldwide businesses are run on a 24x7 basis today, and that number is expected to grow to more than one-half by 2000.
Availability Is Built On Three Pillars
There is a mistaken belief in the industry that high availability is simply a hardware or software product that can be purchased. High availability is not redundant components and quick failover or recovery. Customers will frequently order mirrored disks or cluster technology and think that they have a highly available solution. Although these tools are helpful and usually necessary, additional investments in people, process and technology are also required. High availability must be planned, designed, built, measured, and managed.
Availability is built on three pillars: technology infrastructure, support partnerships and IT processes. It is through a continuous process of investment and quality improvement that service levels required for essential business functions can be met. Investments and quality improvements are usually required in the areas of people, process, and technology.
Technology Infrastructure
Systems featuring high availability are created with a solid IT architecture, and are designed and built around high-quality durable hardware and software platforms that incorporate preventative features, failover capability, tools to minimize planned downtime and diagnostic tools to minimize time to diagnose and repair. The goal of the architecture is to keep the system running. Increasingly common ways to bolster hardware reliability are hot swappable disk drives, disk mirroring; shared disks and memory; redundant power supplies; redundant networks; server clusters and diagnostic technology. Software platforms rely on failover software products and reliable operating systems.
The goal of technology infrastructure is to:
Since human error is believed to account for greater than 20% of all unplanned downtime, the technology infrastructure components must be easy to use and support automated management. The IT organization must also be equipped with proactive tools which provide monitoring, control, and performance optimization.
Support Partnerships
Support partnerships in this context refer to all of the people required to maintain and support the IT environment. These are the people who have the ability to keep the system running, fix it fast if it fails, and fix it once. Support partnerships include your own IT staff as well as all external organizations you use for outsourcing or supporting the hardware and software in your environment.
In order to deliver quality services to your end users, IT personnel must be well trained and must be held accountable for meeting the Service Level Agreements. They must act in proactive rather than reactive ways, and provide the necessary interface to external service providers. The Operations Manager must focus on becoming a Service Manager.
Strong external alliances are necessary to support your internal staff. The following capabilities from partners will assist you in achieving your availability goals:
IT Processes
In many IT organizations the current situation is that processes are undefined or vague, there are poor linkages between processes, and there are unclear roles and responsibilities. This results in inconsistent service delivery, poor customer satisfaction, multiple reworks, periodic work stoppages, communications breakdowns, and duplicate work efforts. The first step in correcting this is understanding and measurement of the current environment. If you cannot measure your current processes, you cannot improve them.
Historically, IT has implemented isolated "point" technical solutions, resulting in numerous islands of technologies that are disconnected and have no clear process linkages. While technology continues to be critical for IT to realize its goal of becoming a service-oriented organization, the focus today is to select and implement process-enabling technologies. These technologies are designed with process in mind, to automate processes and enable strong inter-process communication.
That's why Hewlett-Packard has developed the Hewlett-Packard IT Service Management (ITSM) Reference Model. The reference model, which uses a series of high-level process relationship diagrams, allows Hewlett-Packard and its customers to assess their existing IT environments and to design, implement, and manage new environments with fully integrated processes and technologies. It also helps Hewlett-Packard and its customers determine which processes and technologies should be managed internally and which should be outsourced. The model provides a common language for conducting meaningful dialogue regarding IT service management.
IT Service Management Reference Model
Since the focus of this document is on process improvement, the remainder of the paper will concentrate on the Hewlett-Packard IT Service Management Reference Model. This model is a useful tool for addressing the processes that need to exist in order to provide high availability for mission critical applications or services.
Service Management is a process-oriented approach to delivering customer-focused IT services that meet cost and performance targets. These targets are set in partnership with the line-of-business customers and are embodied in service level agreements.
The Hewlett-Packard Service Management initiative describes a total solution for customers, employing Hewlett-Packard’s wealth of resources in people, processes, and tools. The ITSM Reference Model provides the crucial process link, and can be used to identify and improve IT processes which have the ability to impact availability.
Origins
The Hewlett-Packard ITSM Reference Model is based on a set of industry standard concepts defined in the Information Technology Infrastructure Library (ITIL). ITIL was originally created by the United Kingdom government to better understand the management of services delivered to an end-user community by IT professionals. Over the years, ITIL principles and philosophy have been verified and refined, under the stewardship of an independent organization chartered with its maintenance, from the feedback of IT professionals and end-user organizations.
Hewlett-Packard leveraged its own wealth of IT experience by involving Hewlett-Packard’s internal IT organization as an active participant in the model’s development and verification.
Components
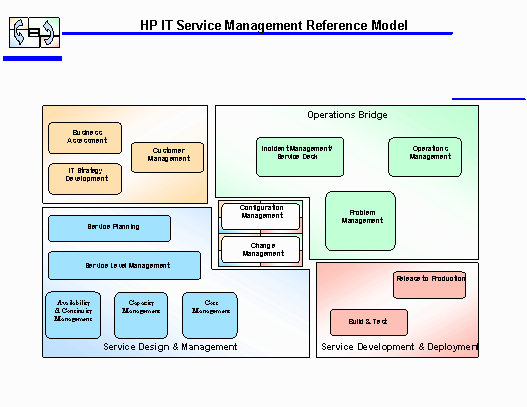
There are four major process groups represented in the model along with two critical processes, Change Management and Configuration Management, which are at the core of the model. The model represents the continuous cycle of process improvement which must go on as part of the ongoing process of Service Management.
The continuous cycle starts with the development of an IT strategy based on business objectives and progresses through design and deployment phases to the operations phase. The core process of Configuration Management establishes and maintains IT’s central asset repository, while Change Management performs the control function. These two processes touch every aspect of IT Service Management. They bring discipline and stability to the enterprise environment. These processes have been placed in the middle of the model in order to reflect their emphasis on coordination, linkage, and control.
Business - IT Alignment
Processes in the Business – IT Alignment process group provide IT with an understanding of market and customer business requirements, determine the value IT will add to the customer's business, and set the IT strategy that will eventually result in fulfilling the identified business requirements.
This group contains strategic processes, which are primarily focused outward toward the market and customers. The three processes included are Business Alignment, Customer Management, and IT Strategy Development.
The Business Assessment process performs a number of activities focused on providing a thorough analysis of market segment business needs. This means that the Business Assessment process seeks to understand each segment’s value chain, their preferences, how much they are willing to pay for a service, how IT can contribute to achieving their business objectives, and how to articulate IT’s position in the segment relative to its competitors. This area must include the process for making decisions on investments in availability.
The Customer Management process establishes and maintains links between executive business managers and the IT services organization. The goal of this process is to enable IT to be a trusted advisor participating in the achievement of line-of-business ("LOB") objectives.
The aim of IT strategic planning is to provide the business with a framework within which it can plan, measure and control the value returned for money spent on its long-term IT investment. The IT Strategy Development process derives and establishes the overall value proposition for the IT services organization by consolidating the various market segment value statements discovered by Business Assessment. This process aligns customer business planning with IT business planning, articulates the broad plan for achieving its goals and objectives, and enables IT to act decisively.
Service Design and Management
Processes in the Service Design and Management process group translate the IT strategy into planned IT services, well-defined service objectives and service levels. Service availability, contingency requirements, capacity plans and forecasts, as well as IT service costing information are incorporated into service contracts and managed on an ongoing basis via these processes.
This group contains medium-term tactical processes, which are primarily focused on introducing new services and managing existing services. All processes in this group depend on the IT strategy. Service performance information -- comprised of data about the quality of service delivery -- from the Operations Bridge is used as a key input to the ongoing management of existing services. Generated in Service Design & Management are service reports for the customer (see Business - IT Alignment), service objectives and measures (see Operations Bridge), and planned services (see Service Development & Deployment).
Within Service Design and Management there are five processes: Service Planning, Service Level Management, Availability & Continuity Management, Cost Management, and Capacity Management.
Service Planning defines service requirements and services, identifies gaps in current capabilities, and builds plans to meet the market requirements for generic services and the customer requirements for custom services. It also translates operational service change requirements into service definition and plan updates. This is where the availability requirements are defined and cost/benefit analysis is done.
The Service Level Management process translates a service plan into its operational requirements (service and infrastructure component specifications). This process also manages the quality and quantity of delivered IT services -- end-to-end, according to a written Service Level Agreement (SLA) or contract. This process establishes and manages the SLAs to provide reliable, cost-effective services based on IT strategy, customer requirements, and IT capabilities. The levels of availability, reliability, and recoverability are included in the SLAs. Service Level Management depends on Availability Management to provide performance reports detailing availability-related services.
Availability & Continuity Management defines, tracks, and controls access to IT resources for customers. It also designs and manages the IT infrastructure to meet availability commitments, and recommends changes in component-level designs and SLAs as necessary. Processes for developing and validating contingency plans and security plans are included here. This area also includes the process of establishing supplier agreements to ensure availability service levels are reached.
Cost Management defines, tracks, and controls service cost structures to ensure cost recovery. This includes tracking actual costs by service and by customer and charging customers for service delivery. Cost Management allows IT to pass along the costs of higher availability to those using the services by getting input from Availability Management.
Capacity Management defines, tracks, and controls IT capacities to ensure infrastructure improvements are ready to meet demands of customers. It is important to ensure that sufficient capacity exists to allow IT to meet availability levels during times of partial failures. Availability needs for additional capacity must be communicated to Capacity Management by Availability Management.
Service Development and Deployment
Processes in the Service Development and Deployment process group develop services and their related infrastructure components (e.g., processes, procedures, tools, hardware staging, software installation, applications, training plans, etc.). Testing is conducted in accordance with customer requirements for the services. Fully tested services are integrated into the production environment where additional testing and implementation are performed prior to service acceptance into the Operations Bridge.
This group contains short-term tactical processes with a primary output of operable, supportable services. The processes in this group depend on services planned in the Service Design & Management process group. Change / Configuration Management processes also play an important part in the success of processes in Service Development and Deployment.
Within Service Development and Deployment there are two processes: Build & Test and Release to Production.
The Build & Test process performs component selection/development, assembly and integration, and testing. Note that when business applications are required, this process also addresses application development. Availability is difficult to ensure unless there is a test environment where all proposed changes can be validated. This process group should also ensure that reliability and recoverability are built into the applications and the infrastructure through the enforcement of standards. There should be a process in this area to identify and analyze potential failure areas in the design of a system or application. The Build & Test process also is responsible for developing component recovery procedures.
The Release to Production process manages the implementation of service components into the IT environment as specified in service design. This should include a process to perform a formal build, test, and integration of all changes. This process retrieves recovery procedures from the CMDB to use in testing.
Operations Bridge
Processes in the Operations Bridge process group work together to provide command, control and support of the IT environment (similar to the nautical reference to a ship's "bridge"). Focused on IT service delivery, these processes comprise the ongoing running, monitoring and maintenance of the IT enterprise environment.
This group contains short-term tactical processes, which are primarily focused outward toward the customer in the form of delivered services. All processes in this group depend on the definition of service objectives and measures (see Service Design and Management) and on production releases of service infrastructure, processes, tools, etc. (see Service Development and Deployment).
Within Operations Bridge there are three processes: Incident Management/Service Desk, Operations Management, and Problem Management.
Incident Management/Service Desk is focused on restoring service availability with minimal disruption to the end user. This process manages and controls day-to-day contact between end users and service providers. Efficient first-level support is encompassed in this process, both for user inquiries and infrastructure events. Incident Management uses operating procedures created by Build & Test to consistently deliver services at the required availability levels.
Operations Management manages and performs normal, day-to-day processing activities required for IT service delivery in accordance with agreed-upon service levels. Essentially, this process operates the IT infrastructure (including computer hardware, software, and networks) required to deliver services. Efficient monitoring will help limit unavailability by detecting problems earlier and by automatically notifying support personnel of failures. The tools used by Operations can be used to gather data on trends that might impact availability. Processes for automatic restoration should also be included in this area.
The Problem Management process of ITSM has two dimensions: reactive, to resolve referred (or escalated) incidents; and proactive, to analyze incident trends, addressing root causes. It includes problem control, concerned with avoiding the same fault, and known error control, concerned with ensuring that long-term solutions are implemented. A process should be in place to immediately escalate recovery of critical applications.
Configuration Management
Configuration Management is a disciplined process to specify, track and report on each IT component under configuration control, referred to as a Configuration Item ("CI"). Data are stored in a logical entity known as the Configuration Management Database ("CMDB"), typically consisting of multiple distinct databases. The CMDB can be used to identify potential availability problems by searching for all installations of a problem component. Availability Management depends on information from the CMDB to understand the constraints in developing the Availability Design and Plan, which is then stored in the CMDB.
Change Management
Requests to make changes to the IT infrastructure or any aspect of IT services are managed and controlled in this process. A rigorous Change Management process will identify, assess, and mitigate the risk of all changes to a high availability environment.
Configuration and Change Management are short-term tactical processes, which are primarily focused inward toward the enterprise environment.
How Can You Use the Model?
The Hewlett-Packard ITSM Reference Model provides a common language to use in understanding the processes required to run a successful IT organization. It can be used to identify the IT processes necessary to deliver quality IT services and to define the required inter-process relationships and business linkages. The process model describes the total solution and can be used as a guide for future investments in people, processes, and technology.
Assess Your Current Environment
Most IT organizations already have some or all of the ingredients of a good IT solution today. What is often missing is the formalization and documentation of the processes and the understanding of the linkages between different processes. This also becomes an obstacle when attempting to discuss the requirements of IT with external service providers to determine whether their possible solutions will meet the needs of the enterprise.
Use the Reference Model to assess your current environment with regard to Service Management. You can identify which processes are currently in place, and whether or not they are working optimally. You can analyze whether critical linkages between processes are in place.
Identify the Desired State
The IT Infrastructure Library suggests best practices which reflect the optimal state of the processes within the Reference Model. This is the desired state, where all processes exist, are documented, and are followed exactly. The correct linkages between processes are defined and followed so that each process has the necessary access to the information from other processes.
Analyze the "Gap"
Once you have determined the current state of your environment and identified the desired state, you will be able to determine the areas that need improvement. The Reference Model can be used as a road map to help you understand the tasks required, prioritize them, and plan for improvement. It can help guide product planning and software development, as well as planning, implementing, and supporting the delivery of new services to your end users.
Since the Reference Model represents a continuous cycle, it can be used over and over for continual process improvement.
Where Do You Start?
Since the Reference Model encompasses the entire IT organization, the amount of work required could seem overwhelming. However, it is possible to prioritize the effort by looking at things as short-term, medium-term, or long-term goals.
Strategic Goals
The strategic goals will be long term; they will stretch out over months or even years. The things considered strategic are all of the processes in the Business IT Alignment group and the Service Planning process.
These goals may take a long time to achieve, but they are the first place to start. The IT strategy must be defined first because it drives all of the other work done by IT. This area is where the customer requirements are identified, the services you wish to provide are defined, and the plan for meeting the needs is put in place.
The first step is understanding your business needs and objectives. Deciding where and how to invest in highly available service levels depends on a clear comprehension of the business benefits and interruption costs for each mission critical, time-sensitive application. This requires identifying which applications are mission critical and the current state of those applications. A clear business case must be made for investments in availability tools, processes, and people development.
Operational Goals
The operational goals are the next step. These are the short-term processes that comprise the foundation of everything that IT does. These processes are necessary to fully stabilize the IT environment. A summary of recent problems or incidents can help to isolate recurring problems and identify problem areas that require immediate action.
Usually, the most critical processes to implement here are Change and Configuration Management, followed quickly by Operations Management. Controlling change and proper management of the environment can be critical in maintaining the availability of a service. The remaining Operations Bridge processes and the processes for Service Development and Deployment should also be tackled as short-term projects, although they may take significantly longer to complete.
Tactical Goals
The tactical, or medium-term, goals are those which provide the services to support the business. Once you have defined your services and implemented them, the remaining processes in the Service Design and Development group should be implemented. These processes will allow you to monitor and measure the services you are providing, as well as to plan for future new services and for improvements to existing services. Once these processes are implemented, the IT enterprise will be controllable and measurable, which means that it can be improved on an on-going basis. The stability provided by these foundation processes is absolutely required before IT can realistically begin delivering true Service Management capabilities to their customers.
Conclusions
There are many opportunities to improve the availability of mission critical applications. But any attempt to do so must include improvements in all of the pillars of availability: Technology Infrastructure, IT Processes, and Support Partnerships.
Having the best technology solution available and strong support partnerships do ensure availability if:
And if the process is not being measured, then it can't be changed or improved. Measuring a well-defined process internally, together with process inputs and outputs, provides an IT organization with the ability to predict process performance over time. This is basic and integral to any continuous process improvement effort. The result of a measured process is that IT can gauge process performance and adjust the process prior to some kind of service failure (indicated by trend analysis). This capability enables IT greater flexibility to changing service demands by allowing proactive process adjustments, rather than the traditional reactive mode experienced by so many IT organizations.
It is important to remember also that no process is an island. This means that defining and measuring any individual process must be done in the context of the greater whole, i.e. understanding and defining the inter-relationships and dependencies between the target process and other processes in the IT environment. Unclear and/or undefined process inter-relationships can lead to false hopes and frustration when the process you just "fixed" leads to breakdowns in other processes - not unlike plugging a hole in the dike, only to find a leak somewhere else.
Credits
At a conference I was at earlier this year, Bob Walker, Hewlett-Packard Vice President and General Manager, Professional Services Business Unit, encouraged us all to "copy from others," since it is not always necessary to recreate everything. Taking that advice to heart, many parts of this paper came from previous documents written by other Hewlett-Packard employees. I would like to thank all of them for their contributions.