 |

|
|
As global 24x7 operations, revenues, customer interaction, and productivity rely more heavily on automated supply chain management, Enterprise Resource Planning, customer management systems, and e-commerce, IT strategy is no longer a competitive advantage, but a competitive necessity. As companies evaluate their mission-critical computing requirements, they realize that IT is no longer just a technical decision; it also is an investment decision. The cost of downtime varies by company, but the conclusion is the same: an outage of any scale can translate to direct costs and indirect costs. In today’s open-computing environment, not only is downtime costly, but it can also be highly visible. Consider the following:
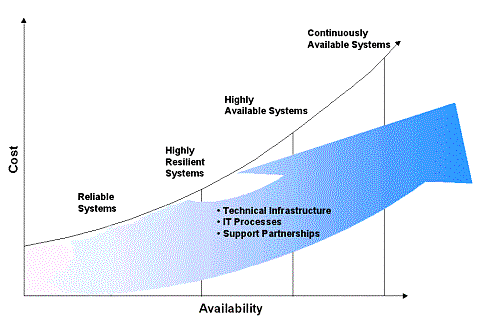
Today’s IT managers want an unmatched level of business confidence, safety, and peace of mind. These benefits ultimately will translate into greater IT efficiency, greater end-user satisfaction, and increased company profitability. With the right mindset, strategy, and investments in technology, IT processes, and support partnerships, IT managers can be assured they will meet their requirements and expectations of service. What is High Availability? System availability has come a long way. What once were costly, complicated options to make computing resources accessible are now critical components in day-to-day business activities. From improving productivity, to increasing profitability or enhancing service, businesses—large and small, in virtually every industry—depend on the availability of its information systems. According to International Data Corporation (IDC): "A system is considered to e highly available if, when failure occurs, data is not lost and the system can recover in a reasonable amount of time." But just what constitutes "reasonable?" The specific will differ with each business’ requirements and its tolerance for outages. The following hierarchy defines high availability in terms of the amount of downtime per occurrence. As customers s move up this hierarchy, the time associated with either planned or unplanned downtime decreases and the need for availability increases. |
 |
|
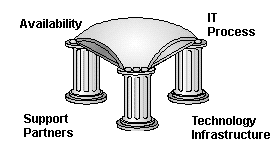
Or, as quoted in CIO magazine on May 1, 1998, the question to ask of every system is "What is your threshold of pain—that is, the downtime, whether scheduled or unscheduled, that your business can tolerate?" Reliable Systems Establish the baseline for measuring availability. At this level, system interruption is limited to six hours, plus database recovery. Infrequently planned maintenance may occur, typically after operations hours. Although annoying, occasional downtime is within expectations if data integrity is preserved. RAID devices or single system mirroring are examples of technology infrastructure for reliable systems. IT processes for reliable systems should include light resource monitoring, routine backups and formal IT procedures. Support partnerships should include basic preventive maintenance with standard response such as telephone response, help-desk support and ongoing system and application updates. Highly Resilient Systems The second level of The Continuum, has regularly planned maintenance that is scheduled outside regular operating hours and can be re-scheduled if required. Service interruption is limited to 30 minutes, plus database recovery. Technology infrastructure for highly resilient systems is achieved through enhanced failure recovery, individual component redundancy and/or add-on products, such as disk mirroring or disk arrays, to eliminate single points of failure. IT processes require performance and system monitoring with disciplined IT management processes. Though they have disciplined processes, these customers tend to not follow these procedures or have proper training associated to these processes. They may be comfortable with one aspect of IT Management, such as configuration management, but have gaps with other processes. Heightened vendor time-to-repair commitments and proactive risk management with personalized support will satisfy the support partnerships. Highly Available Systems Require moving applications from one system to another for infrequently planned maintenance. To maximize availability, the second system continues to service requests while the original system is updated. Any unplanned downtime events that may affect performance have rapid failover and recovery technology and processes to limit the service interruption to five minutes per event (plus database recovery). Technology infrastructure for highly available systems is achieved through multiple, independent computer systems arranged into a networked configuration (clusters). High availability software, such as MC/ServiceGuard, enable the systems to interoperate. Services originating on the failed system are moved to another system within the environment. Most highly available systems incorporate redundant network. IT processes provide proactive enterprise application and infrastructure monitoring with comprehensive IT service management. These IT processes tend to be followed or outsourced with strict reporting procedures. Many also have service level agreements (SLAs), both internally and with vendors, most often internally and many with bonuses tied to achieving these SLA's IT may also be measured on helping to meet the companies objectives. Highly available systems require significant proactive support for all IT processes and restoration commitments. Strong partnerships not only enhances the vendor's understanding of the business, it also allows the vendor to recommend changes to the IT environment and processes. Continuously Available Systems Offer maximum availability on The Continuum, providing 7x24x365 operation, regardless of planned or unplanned downtime. Transparent application recovery and transparent client reconnection application are key elements of continuously available systems. Service interruptions should be fully automated and transparent to the end user and last only three to 15 seconds, including database recovery. Planned maintenance activities, such as database backup, are performed online. Continuously available systems require complete system interconnect redundancy. This is achieved through specialized fault tolerant architectures designed for continuous operations. The customer may invest in data center separation for disaster risk management. IT processes are characterized by highly stabilized operating environments with comprehensive automated IT service management monitoring and recovery procedures. IT job performance is tightly linked to achieving near continuous availability and meeting company objectives. Vendor support features extreme escalation procedures, maximum on-site support and service level guarantees. The vendor also plays a trusted advisor role, making proactive suggestions to help meet organizational goals and improve system availability. The customer, in turn, relies on the vendor's knowledge of their business strategy to implement new technology and leverage business trends. How to Achieve High Availability The strength of an IT environment is limited by the strength of its weakest link. If any component is weak—regardless of whether it is hardware, the operating system, the network, middleware, or applications—the solution collapses. Building effective, highly available systems requires a strong foundation. This foundation is supported by three pillars: technology infrastructure, IT processes, and support partnerships. High Availability is not a product that can be purchased. Rather, it is a goal achieved by planning, designing, building, measuring, and managing. IT managers must invest in each pillar to meet specific availability requirements. Investing in only one or two pillars cannot address all of the causes of downtime and will not provide the total solution to meet a customer’s availability needs. |
 |
|
Technology Infrastructure The first pillar, a reliable and resilient technology infrastructure, applies to all hardware, software, and network design. The actual components are built for supportability and reliability. The whole infrastructure is designed and implemented with the business goals in mind and aligned and made production-ready. High availability technology includes mirroring, failure recovery and switchover, clustering, and redundancy. High availability technology is becoming more resilient and have more "self-healing" features. Investments in technology scale across from simply mirroring to full redundancy and should be matched to the criticality and potential loss of the application. IT Processes Change is constant and prevalent in open, distributed systems. While this flexibility is key to aligning IT with business changes and movements, it can also present a challenge to manage change and the impact to configurations. But, careful assessment, planning, deployment, and operational processes ensure change is managed in a way that minimizes risk of downtime and optimizes performance and security. Easy, automatic IT processes includes limited resource monitoring, routine backups and formal IT procedures. As the hardware and operating system becomes more resilient and reliable over time, human error takes on a larger percentage as the cause of unplanned downtime. To lessen the frequency and impact of operator error, mission critical systems must be managed effectively. Proven processes can help isolate a problem, actively managing the cause and impact, or can prevent a situation from escalating. IT Service Management processes should be comprehensive, and include the following: build and test, release to production, problem management, disaster recovery planning, operations management, service desk, configuration management, change management, service level management, availability management, and capacity management. Support Partnerships A growing area of concern for IT is how their support providers will support their operations, ensure systems are production-ready, respond to problems, and supplement their own internal staffs and skills. In seeking mission critical service, IT managers want to establish strong partnerships with the support provider. They want more personal attention; a proactive partner who will look out for their interests and who regards the organization’s downtime as seriously as if it were its own. The right partner can assist with technology selection and deployment. Services for mission critical environments help customers achieve high availability by offering proactive services that prevent potential problems, reactive services that can diagnose, notify, and restore data availability, and account teams that know the IT environment and business needs. The support provider needs to demonstrate that they are committed to investing in skills, tools, and capabilities to ensure their customers uptime. Proactive Services: Proactive services ensure planned downtime is minimized and unplanned downtime is prevented. Proactive services can encompass modules of operating system upgrade planning and implementation, patch management, operational assessments and benchmarks, and performance optimization. A strong partnership increases the vendor’s understanding of the business and allows the vendor to recommend improvements to both the IT environment and the processes. Repair/Restore Commitments: Reactive efforts are necessary to restore availability in the event of a failure. Problems can be diagnosed remotely and resolved faster with the highest level of reactive service, built-in supportability that incorporates the latest technology and a well-educated staff. The clear objective is to get the system functioning again before solving the technical problem. Predictive capabilities often are designed into the technology. They include such features as online diagnostic tools or software that alerts staff to impending failures or to disks and components that can be swapped or added while the system is still online. Rather than just respond to customer problems, whether they’re called in or notified via remote technology, support providers need to commit to a repair or restoration time. To deliver this, a worldwide infrastructure, special parts logistics, excellent diagnostics for troubleshooting, and assigned account teams are a necessity. Account Teams: Assigned or dedicated account teams ensure that the on-site engineers, response center engineers, and even contract administration teams understand the IT environment, the technology challenges, upcoming plans such as migrations or implementations, and business goals and dependencies. This partnering and intimacy allows for better support, recommendations, and response. Comprehensive Services for Environment: Complex mission-critical environments today include applications running on mixed operating systems, a dependency on the network, amazing requirements for storage, and users with a variety of needs. Support providers need to be able to provide support for UNIX and NT, network devices, and storage solutions to provide effective mission critical solutions. Service organization Alliances: In order to provide these solutions, no support provider can do it alone. Vendors will increasingly form alliances not just in R&D, but also on the services front. Vendors are forming alliances to integrate their proactive services to encompass the complexity in today’s systems. They are sharing reactive processes and tools. They are cross-training teams and aligning support organizations. A service and support alliance in the mission critical space means more than just a "gentleman’s agreement" or call transfer; it requires integrating services and account teams in order to ease vendor management and improve customer availability. HP High Availability Solutions Hewlett-Packard is firmly established as the leading supplier of mission critical solutions in the open client/server marketplace today. Through its efforts to meet the high availability requirements of customers worldwide, Hp has created an expansive portfolio of mission-critical products and services. HP understands that high availability also means high reliability and performance. Technology infrastructure is a strong foundation for the entire spectrum of HP products. HP9000 Enterprise Servers are designed from the ground up to provide industry-leading levels of reliability. MC/ServiceGuard, HP’s industry-leading, high availability software, protects network configuration and keeps mission-critical applications running. HP High Availability Disk Arrays ensure reliable access to data through storage solutions. HP NetServers offer 8-way mission critical computing for applications on Windows NTä . IT processes ensure management and operations with tested and defined procedures. The HP IT Service Management reference model (ITSM) is a process model based on a set of industry standard concepts. HP offers HP Consulting services to help customers assess, plan, deploy, manage operations, and manage change. HP OpenView, the industry-leader in availability management, provides tools to help IT manage and measure the processes with ITSM as a framework. HP Mission Critical Services HP offers comprehensive services that enable customers to scale and manage their specific availability needs based on their computing environment. The services, including support services, consulting services, disaster recovery, are designed to help customers meet their business goals. The services are designed for customers running mission critical applications on both HP-UX and Windows NT platforms. HP Critical Systems Support is a modular, flexible service that provides proactive services for critical environments and reactive support for hardware, o/s, network devices. A modified offering for SAP R/3 environments provides Basis-certified engineers on the account support team. HP Scalable Services and Support for Windows NT is a comprehensive, flexible solution with proactive account support and change management and fast and full reactive support. A modified service is also available specifically for SAP environments.
Mission-Critical Server Suite HP Mission Critical Server Suite (MCSS) is a pre-configured, open systems solution that is designed to meet stringent high availability and performance requirements. Based on HP9000 Enterprise Servers, the suite packages the critical components for a highly available environment and offers an unprecedented solution with 99.95% uptime. The solution packages together:
A Case Study: Millions on the line for VISA On an average night, VISA settles over a billion dollars in purchases, checks or cash advances for the 15,000 banks that own the credit card company. If ever there exists a mission-critical environment, VISA is it. Operating around the clock every day of the year, VISA requires 100 percent availability from the systems that daily process, settle and clear millions of transactions worldwide. Even a 15-minute outage can affect several hundred million dollars worth of processed transactions. VISA’s top three priorities for improving availability are: commonality of systems and services; control; and stability. The confidential nature of its business demands secure transactions which require total control. VISA also requires a stable, trustworthy operating system on which it can fall back, if necessary. VISA is gradually moving from IBM mainframes to client/server networks to reduce costs and achieve better scalability. It currently uses a mainframe as well as 12 HP 9000 Enterprise Servers: four K-460s; five K-520s; and several Series 700 workstations. Jim Long, director of application development at VISA’s San Mateo, Calif. Data center, cites the SMP architecture of the K-Class Enterprise Servers as a real advantage of HP "We value HP for its capacity planning its performance tuning. Nothing else is quite as reliable. HP came in first as a UNIX box." To ensure high availability for its client/server networks, VISA contracted with HP to provide the maximum level of support, Business Continuity support. This service is designed to identify and prevent problems before they impact business operations. "We also appreciate the way HP takes an interest in our business," added Long. "We need a partner who really tries to understand our particular needs and who will answer questions in our environment. This helps VISA sustain our growth and stay number one." |
 |
|
5nines: 5minutes; In early 1998, HP announced its 5nines:5minutes ™ High Availability Vision. Through solutions of technology, mission critical services, and partnerships with other leading vendors. HP’s 5nines:5minutes program defines how HP will deliver an industry-altering 99.999% availability in pre-defined, pre-tested customer environments. Supported by its strategic partners, HP will maximize uptime as seen by the end-user, delivering true end-to-end availability.In mid-1998, HP announced the first tangible products and services to deliver on this vision by including Cisco switches and Network Availability Services in Mission Critical Server Suites, by introducing HP MetroCluster with EMC Symmetrix Remote Data Facility, and by announcing HP and Oracle integrated mission critical services available in 4Q 1998. The 5nines:5minutes program is testimony to HP’s commitment to its customers as IT faces more and more demands for applications to be up and data available; business success and competitiveness depends more on IT moving into the next millenium. HP will continue to set the standards for high availability solutions and providing leading solutions for mission critical environments with the best technology, leading management of IT processes, and excellent support partnering with our customers. For more information see: www.hp.com/go/ha or www.hp.com/go/mcservices Technical information in this document is subject to change without notice. Copyright Hewlett-Packard Co. 1998 All Right Reserved. Reproduction, adaptation, or translation without prior written permission is prohibited except as allowed under the copyright laws. 5nines5minutes is a registered U.S. trademark of Hewlett-Packard Co. Windows NTä is a registered trademark of Microsoft Corp. UNIX ä is a registered trademark of The Open Group |