
INTEROPERABILITY AT THE ENTERPRISE LEVEL - SAY WHAT?
Adapted from an essay in the September 1, 1997 edition of Plant-Wide LBN
The need for interoperability is growing exponentially at the enterprise level. Until now, the main emphasis has been only for specific instances of need ... mostly at the departmental level. To ensure that the ERP vendors do not have easy access to their host systems, they use all sorts of discordant stuff (sorry -- languages, proprietary code, arcane conventions, look-and-feel, etc.) And while the vendors themselves are little more benevolent at interfacing, (mostly one way only -- their way), they don’t have a high regard for interoperability either. BUT DISTRIBUTED COMPUTING IS NOW UPON US! Many MIS managers are beginning to feel the pinch and, frankly, it’s about time. Their tolerance for pain has been rather high with respect to interoperability...until now. Aiding in this malaise has been the manufacturing folks who, until 1991, make half of all the MRP buying decisions -- all the time, totally ignorant of interoperability (or at best simply ignoring this important issue). With no "heat" on them, MRP/ERP vendors went along and ignored the problem as well. Many of today’s application vendors who appear technically competent do not have the wherewithal (or desire) to make the journey to scale to the enterprise level. Many solutions are "architecturally challenged" (politically correct terminology please note) with respect to interoperability. Friends, this war is about control of your wallet and vendor survival in the future of computing. This is why it is essential that you, our readership, must think out the entire interoperability problem when selecting a vendor(s) because, if you don’t, we would like to wish you well in your next job now.
I: introduction
For some managers, the march toward the virtual corporation is an unwelcome but necessary evil. For others, it is the key to a bright and promising future. Whatever the view, all agree that significant change in the business process change is, if nothing else, inevitable. The march started with the shift from make-to-stock to make-to-order as retailers, finished goods manufacturers and original equipment manufacturers (OEMs) sought to eliminate inventory and push it farther down the supply chain. While the up-side of this new direction is reduced costs, the down-side is more dependence on supplier systems, which is to say extending the tentacles of one corporation into the bowels of another. Supply Chain Management, Value Chain, Demand Flow Leadership, Vendor Owned Inventory, Just-in-Time Manufacturing, and Quick Response are just a few of these emerging virtual business processes that have already been put in practice.
Although many have reacted to the virtualization of business by ‘extending’ their applications and declaring Internet solutions, doing so without understanding root causes and needs is little more than a continuation of the reactive approach to satisfying business need and will ultimately be unsatisfactory. What is really needed is an effective and responsive framework and an infrastructure that will satisfy any business process formation or any virtual enterprise requirement. By so doing any number specific solutions, including an Internet, electronic commerce, or never before thought of ones, can be quickly and effectively be put in place. Thus, we can have an environment for business without barriers.
The foundation of this barrier-free environment is interoperability -- the ability of one system to process information to and from another without requiring either system to make changes to accommodate the other. According to the editors as Plant-Wide, we have a long way to go and we are not doing a very good job of getting there. Sure, Electronic Commerce (EC), after a frustratingly slow start, is finally here to stay and the Internet, that electronic highway to the future, has become a global business reality. But neither of these ‘technologies’ address the real problem -- that we have become trapped in the bureaucracy of our own application code. This is all we know. Have a problem? Solve it with code. More and more code. We are drowning in code.
Becoming ‘interoperable’ is not easy – it requires a fresh approach, a new way of thinking. It requires the acceptance that legacy, code-based systems have been stretched beyond their limits. Our thinking has to start all over again, from the ground up. It has moved to an open, rules-based object architecture, an architecture where the ‘meaning’ is in the semantics of the business message and not the application. It has to cross the chasm.
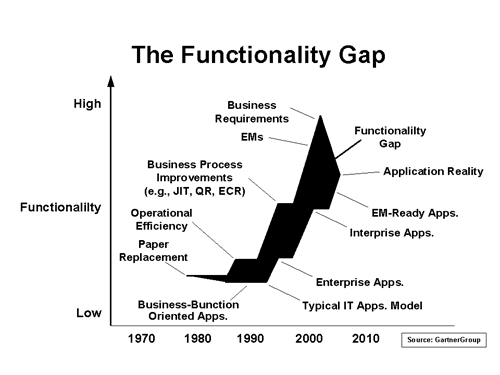
The chasm in question is what the GartnerGroup calls the Functionality Gap. Since the beginning of time, applications have been developed in the domain of computer languages and programming code. As applications added more functionality, the amount of code increased. With the move toward distributed processing and enterprise level functionality, the amount of code increased at an even greater rate. The result, as depicted by the plot on the right in the diagram above has been a gradually flattening curve. As more code (and the time to program, compile and test it) is added, the curve moves farther to the right. Given enough time, it will die of its own weight.
At the same time, the business community has been accelerating its demands to improve their business processes. They want to do business quicker, better, faster, cheaper. Their goal, as depicted by the plot on the left, is decreased cycle times and increased functionality at an exponential rate. The curve is moving to the left and becoming more vertical. The result is a widening gap that, as we head into the next millennium, will approach 5-7 years. The gap clearly shows that manufacturing systems are losing ground to new trends in business solutions. The gap has become a chasm.
Crossing this chasm, although no walk-in-park, was made easier by understanding the concepts of rules-based (semantic) messaging and the constraints for application-based logic. To help achieve a better level of understanding and gain an appreciation of how and why it is the ERP systems technology leader going into the 21st century, SSA has prepared this White Paper. As you read it, please consider the following...
 |
II: Understanding the need for interoperability
We need to reduce costs and improve efficiency, but we seem to trouble finding where and how to do it. We make two false assumptions -- that technology is the answer and that it can only be applied in our own back yard. We forget that it is not technology itself that reduces the costs, but the resultant change it brings to our business process and that those processes are becoming increasingly dependent on those of the other players in our supply chain. And so it goes. We end up looking in the wrong places.
Finding the right place…
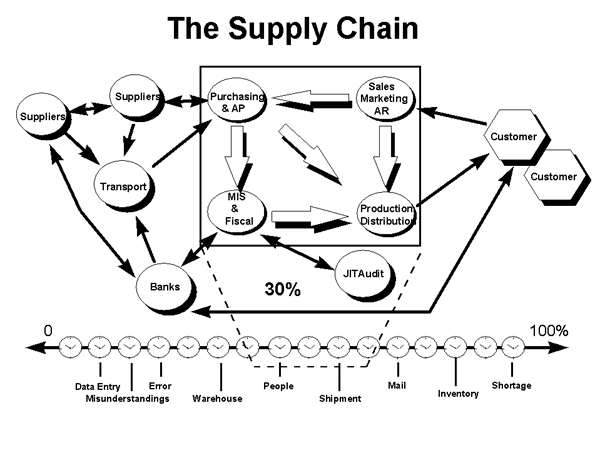
The successful search for an interoperable solution starts before the replacement technologies are conceived, designed, installed, and locked into place. It begins with an examination of the entire trading cycle as it is today. The cycle begins with the a customer’s order. The manufacturer passes the order through the usual intra-enterprise activities -- sales, marketing, manufacturing, distribution, purchasing, accounting (fiscal), and systems (MIS). Since this is the age of distributed manufacturing -- we do not want to make things that others can make better, cheaper-- the manufacturer turns to outside support (inter-enterprise activities) from suppliers, utilities, transportation, banking, communications, government, and other providers of goods and services that are needed to make the product. The combination of the ‘intra’ and the ‘inter’ defines the length and breadth of the supply chain from the customer’s customer to the supplier’s suppliers. When measured with a timeline, it also defines the total cost of the finished product.
The ‘trick’ to reducing product cost is to shorten the timeline. By reducing or eliminating wasteful and redundant processes - data entry, data conversion, errors, communications, waiting for information, waiting for inventory, programming and re-programming, the mail...manufacturers can stay competitive. According to Michael Hammer, the re-engineering guru, these processes can be as high as 99% of the total time expended to make a product. The math is simple. Since most of the time (70%) is inter-enterprise or spent going from ‘outside the box’ to ‘inside the box,’ so is most of the cost. If 99% of the 70% is waste, the best results have to come from outside the box. Taking the easy route and focusing only within is not the answer. No matter how hard we might try, improvements to the ERP or MRPII systems itself can only ‘solve’ 30% of the problem. We must look to inter-enterprise functionality and interoperability if we are going to achieve significant results. This is the right place -- land of interoperability.
…and then finding the right technology.
Having found the ‘where,’ we can move on to the ‘how.’ The first step toward how to implement interoperability is to accept that no business is an island and that a company’s business systems can no longer be confined to internal processes and programs. They must now become part of a much larger and more complex inter-enterprise system that depends on its trading partners -- customers at the front door and suppliers at the back. This means that as we make-to-order, carry our customers inventory, and require our suppliers to do the same, the business systems that we use to support each link in the supply chain must become interdependent. To become interdependent is also to become interoperable.
The problem is that no two businesses, much less their business systems, are the same. Even two businesses with the same brand of business system will not use that system in the same way. Everyone is different and this is not easy or likely to change.
But there is no reason to change…if we can find the right technology that will enable interoperability.
III. overcoming current thinking
Breaking old habits is never easy. Overcoming our love affair with code is going to be tough. We have to change the way we think. Therefore, if we are going to embrace interoperability, we have to look beyond just exchanging data. We have to exchange business rules and other information as well. We have to add content and intent. And, we have to find a replacement for our code-based architecture.
To do this we have to understand the difference between integrating and interfacing data and the role of the Application Program Interface (API). We also have to learn about logic and messaging and the role they play in the interchange of information. And finally, we have to become comfortable with business semantics as they are at the center of the interoperable solution.
Integration
Integration is the direct transfer of data from the field and file structure on one application to the field and file structure of another. Integration requires application interdependency. Since all logic resides at the application level (and the sending and receiving applications are unknown to each other), the exchanging applications must have a thorough knowledge of each other’s application programs as well as the underlying business logic. Even if an Electronic Data Interchange (EDI) translator is used to minimize this interdependency, the application must be EDI enabled and the EDI software must be applications enabled.
Since processing logic can only be programmed into an application by those who have an intimate knowledge of the application programs and file structures, integration is labor intensive, time consuming, restrictive, and very expensive. Programming, coding, compiling, and testing are measured in weeks and months. It is for this reason that integration has seen very limited use.
Interfacing
When most of us say we have ‘integrated’ with our trading partners, we have, in reality, only interfaced. This is for good reason -- interfacing is by far the easier and cheaper to implement. Interfacing is used by virtually all e-mail, EDI, graphic design, and translation software vendors as it reduces or eliminates many of the problems caused by the interdependency of different applications.
Interfacing is achieved with the help of a flat file or ‘flat file interface.’ A flat file is a neutral file where the data to be exchanged is stored in a pre-defined format. For inbound information, an API must ‘go’ to the flat file, ‘pick up’ the data, and transfer it to the host application. For outbound information, the API delivers the data to the flat file for processing by the external interchange software.
EDI, a neutral form of information exchange based on public standards, gives of an excellent example of how data is interfaced. The EDI data is delivered from a Value Added Network (VAN), ‘opened’ by the translation software, and ‘mapped’ to the flat-file. The mapping process converts the data from the highly structured, variable-length standard formats of EDI to the fixed length format of the host API.
The mapping part of the process is rules-based and relatively easy to do with point-and-click screens and table driven software. It is measured in hours and days. Updating maps requires re-configuration, a process that is also measured in equally short terms.
Applications Program Interface (API)
The API part is another story. Because of the proprietary and monolithic nature of host applications, data from external sources is rarely in the exact format of the host file and field structure. It must be processed by programs that ‘know’ how to make the necessary conversions and direct the data along the right ‘paths’. This is why the API part of the journey is considerably more complex and time consuming.
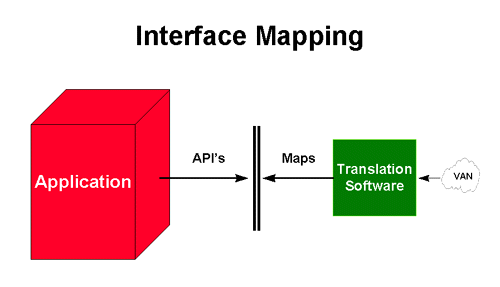
API’s are ‘hard-coded’ programs that ‘integrate’ with an application at much lower costs than direct integration. API’s are intended to be re-useable, however, in actual practice, a separate API is often needed for each set of data. Even with the EDI standards, companies find just enough variation in the way they structure their data to require separate API’s for each message type and for each trading partner relationship. In other words, hundreds, if not thousands, of API’s are or could be required depending on the nature of the relationships and the variations in the host applications.
Although less expensive than direct integration, creating, coding, and testing API programs is still measured in weeks and months. Updating API’s requires re-programming which also means changing the code. This is equivalent to modification of the system and some degree of re-implementation. It is also expensive and time consuming.
Logic
The understanding of how application-based code and API’s have become the main obstacles to interoperability requires an appreciation of the difference between data and logic.
Data by itself has no obvious logic. However, the processing of data requires logic in order for it to be useful. When data is manually entered by humans, for example, the logic of how to ‘use’ the data is based on known information or experience.
Another example can be found in how we use a screwdriver. A screwdriver can be used to turn a screw (its intended purpose), clean dirt out of a crack, or stir the soup on the kitchen stove. It is not the screwdriver that decides how it will be used. By itself, the screwdriver has no function - it is just ‘data.’ It is the user that decides ‘business’ need (logic) that make the screwdriver become useful.
The same principle can be applied to moving data between applications. The purchase order number found in an electronic purchase order, for example, is just a number that has no specific use until it is linked (by the application logic) with a business process. It can be used in a variety of ways such as identifying a customer order or creating a billing invoice. Deciding which way requires logic from a human (for manual data entry) or in the case of direct interchange, from the application program logic.
Unless provided by a human, all of the logic must be provided by the application. This means that the application architecture is in ‘control.’ Separate programs are required for all variations in logic and re-programming is required for all changes in logic. But we just cannot provide enough programs and programming to cover all of the logic. We need to find an alternative method of ‘dealing’ with logic.
Messaging
Messaging, or the packaging of data in a business context, began as little more than an electronic equivalent of a paper document with application access via batch file or dumb terminal (green screen) emulation of the document. The type and format was defined by the application (the screen format) with humans making the business decisions as the data was being entered. Over time, as the scope of electronic messages grew to meet the increasing number of electronic trading partners, the use of standards and standard formats became popular, if not a necessity. However, as users integrated these ‘standardized’ messages with their applications, they soon found that they had to create a separate string of code for each type of message from each of their trading partners. Although the basic message formats remained relatively unchanged, the differences in the selection of data elements and the codes within those formats made each message a ‘custom’ event. With the acknowledgment that agreement on data formats was not enough, the business community has now realized that the benefits from using standard formats was being lost. Business rules in an electronic form and business semantics are now being added to the equation.
Messaging will continue to grow and become a greater part of the solution. The next step will be intelligent messaging based on the use of business semantics. This is an important step and because of this its significance will be examined later in this document. Before we do so, we need to learn a little about business semantics.
Semantics
Since their inception, the purpose of business applications has been to the replacement of paper processes with computer (electronic) processing. Customer order management, for example, evolved from the paper purchase order. But not all purchase orders are the same so additional logic had to be added to the application to account for the differences. Only a limited amount of logic in the form of code identifiers and format descriptors can be added to data.
Linking the enhanced data with the business "rules’ is still a problem. For example, the purchase order number is the initial candidate for mapping (integrating) to an application. All customer order entry applications have purchase order number fields, so mapping the data as is appears to be rather straight-forward. However, on closer examination, not all order entry systems can process the type (business purpose) of purchase order. A purchase order can be a new order, an order change, a blanket order, multiple order, or a cancellation. This information is either ignored (the application only has one type of purchase order) or is ‘resolved’ by the data entry clerk.
The solution is to move beyond field definition and on to how to populate a field where the business logic becomes the primary factor. This requires the use of semantics. Semantics are the ‘verbs’ and action words that describe the context of the business for the application. They are defined by the business environment. The help provide the content and intent of the business relationship.
If the semantics can be part of the business message, then the need for logic at the application level can be reduced. If customer order management can process generic ‘orders’ and rely on the semantics within each order to describe the specific business purpose, then that functionally does not need to be programmed in the application. Once freed from the constraints of its own making, applications can then become interoperable.
IV. semantic messaging
Semantic messaging is messaging with its own logic. It is the rules-based alternative to code-based application logic. It makes the difference. A good way to understand the difference between messaging and code-based architecture is to compare the seemingly similar but actually quite different environments of motor and rail transportation -- the world of trucks and trains.
Trucks and Trains
Trucks are to messaging as trains are to code-based structured architecture. Trucks and trains both transport physical objects. Computer programs do the same for information and data. Although what they do is the same, it is how they do it that makes the difference.
Trucks can go where they want, when they want. They can operate at will within the general architecture of the highway system. The control is literally ‘in the driver’s seat.’ All that drivers need are some instructions (messages as to where to make a delivery) and some rules to follow (the rules-of-the-road.)
Trains, on the other hand, are ‘controlled’ by their infrastructure. They can only go where the tracks go. The train engineer can only stop, start, or change speed. If a different destination is needed, someone else must throw the switch. If there are no tracks to the desired destination, new ones must be laid. In computer speak, coded paths are the ‘railroad tracks’ of computer programs.
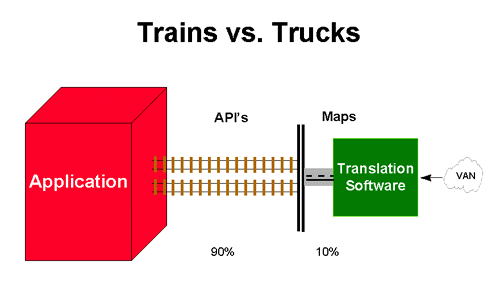
In a data processing environment, information (data) on ‘trucks’ can go anywhere in the system. New information only requires new instructions, and new messages. Information on ‘trains’ can only go where the programs (tracks) ‘say’ it can go. Thus, new destinations require new ‘tracks’ and the new programming, coding, compiling, and testing that comes with it. The concept is easy to understand when presented to scale. Messaging (trucks run on highways) takes about 10% of the ‘integration’ effort. API’s (trains), on the other hand, run on tracks (program code) which comprises about 90% or the ‘integration’ effort.
This is why code-based architecture is expensive and needs to be replaced with messaging. Code-based programs, transactions, and databases embody pre-defined snippets of business functionality. They are becoming increasingly difficult and time consuming to build and even more risky to change in order to satisfy new business realities. Code-based architecture has become a barrier to doing business.
Messaging Attributes.
To illustrate how semantic messaging can work in the application environment is to understand how it works in our everyday business life. When you think about it, semantic messaging is exactly how humans communicate. In fact, it is really the only way they can communicate. If we can make a computer behave like humans instead of the other way around, maybe we will have something.
Consider this scenario for ordering food at your favorite fast food restaurant. You place your order, pay the bill in advance, and with receipt in hand, you wait for your order number to be called. Finally, the message is heard over the PA system: "Number 26, your order is ready."
The message has four key attributes that distinguish it from traditional data transfer: semantics and logic, the ability to be sent and received and understood by the receiver, state transformation, and publish and subscribe. Understanding each of these attributes and how they work together is key to understanding the significance of the semantic messaging concept. It can also be used to illustrate messaging in terms of API’s and client/server architecture.
Semantics and Actions A message has to contain a mix of semantics and actions in order to make sense and have a purpose. Number 26 and your order are the semantic terms, is ready is the action required or purpose of the message. The semantics and actions, although interpreted differently by each receiver depending on the business need, are generally agreed upon in advance as part of commonly accepted business terms and logic – the ‘rules-of-the-road.’
Sent and received and understood by the receiver We have all heard of the proposition of the tree that falls in the forest -- does it make a sound if there is no one there to hear it? The same concept applies to a message. Although data is sent and received all of the time, most of it is never used and ends up in the bit-bucket. This is not the case with messages. The message "Number 26, your order is ready" must be sent and received and understood by the person who placed order Number 26 in order to qualify as a message. No matter how many times is sent, if no one comes to pick-up the order, then it is not a message. The same concept applies to message transfer between business applications. Accepting a message in an application as data and not understanding what the message is all about does not make it a semantic message. This is because a message must result in a state transformation.
State transformation The message "Number 26, your order is ready" (an event) causes state of the order (Number 26) to change and that results in the customer coming to the counter and picking-up the order (another event). To change a state, a message must make sense…it cannot be nonsense. Saying "Number 26" or "your order is ready" separately, one without the other, is not a message because no action can be taken. It is only the movement of data.
Publish and Subscribe This is the attribute that makes messaging really work. In a traditional data processing environment, data is either pushed or pulled. To push data is to send it to a known destination. In the restaurant example, the employee behind the counter, knowing where the customer was sitting, would go to the customer and say "Your order is ready." The converse, pulling data, is like querying a database for specific data. To pull data about the status of Order Number 26, the customer has to make a trip to the counter and ask, "Is Order Number 26 ready?" From a processing point-of-view, pushing data is very efficient, but from a set-up and implementation point-of-view, it is very inefficient. Pulling data is just the opposite. It is easy to set-up but when is comes to results, it is not particularly efficient. Publish and subscribe has the best features of push and pull without the short-comings. The employee broadcasts (publishes) "Number 26, your order is ready" to everyone on the restaurant and only the person who understands the significance of Number 26 takes action (subscribes). The order is picked-up and taken to a table or removed from the restaurant. A change of state is made to complete the event.
API’s and Client/Server
The above scenario, taken a step further by comparing a fine dining restaurant with a fast-food restaurant, can be used to illustrate the difference between API’s and semantic messages. In a regular restaurant, a waiter ‘links’ the customer with the kitchen just as an API links one application (or workstation) with another application. The waiter brings the necessary information to the customer (menu, specials of the day), takes the order, ask how the food is to be prepared (type of dressing, rare or well-done) and delivers the results to the kitchen. The dining experience becomes a tailored ‘program’ as the specific wants and needs of each customer move back and forth along the customer-kitchen ‘API.’ The customer and kitchen become very interdependent.
In a fast-food restaurant, the opposite takes place. The clerk behind the counter (the ‘server’) and the customer (the ‘client’) remain very independent. The server does not care what the client does with the food (add too much mustard, give it to the dog) and the client does not care where the food comes from or how it was cooked. Their only connection is with a few messages ("I want a hamburger." "That will be $2.50." "Number 26, your order is ready.")
V. Configureable Interoperability
Configurable interoperability -- the ability to set-up and execute an interoperable relationship without the constraints of programming or re-programming – is made possible by ‘splitting’ the logic between the application and messages that drive that application. The degree to which it is split depends on the situation. As humans, for example, the more (of the logic) we know in advance, the fewer the words needed in conversation. We say "I know what you mean." The conversation is short and inflexible. However, when we say "I don’t understand", the logical center-of-gravity shifts to the messages being exchange. Although it takes longer, the conversation is more flexible and the exchange is more configurable.
The ability to use semantic messaging to distribute logic is at the heart of configurability. Consider, for example, how the ability to split logic adds excitement to the game of football. The players have to be ‘programmed’ in advance by studying (loading) the play book and participating in practice. During a game, the quarterback decides (in the huddle) which play the team will execute on a down (he selects the correct program) and the call number to execute it. At the line of scrimmage, the quarterback says "Hut 1,2,3.." and the play is executed. Almost all of the logic is in the pre-selected play. His message, the ‘hut 1, 2, 3,’ is just data that executes the logic. However, if after calling the play in the huddle, the quarterback decides at the line of scrimmage to change the play, he calls out what is known as an ‘audible.’ He says "California, six-right, 1,2,3…" He has sent a semantic message that gives new instructions, that has new meaning, that reconfigures the down and the game. He uses the audible because it is more efficient - less time consuming. Otherwise, without this capability (messaging), he would have to call time-out, return to the huddle, and reprogram the down.
With manufacturing systems, configurable interoperability is achieved with the tantalizing combination of semantic messaging, electronic commerce, and object technology.
Semantic Messaging Although applications can ‘interoperate’ with complex, code-based programming, it is the semantic messaging that gives it its configurability. Once in place, configurable interoperability enables businesses to be more agile, more efficient, more independent, and more interdependent. It helps them to ‘interoperate’ with many more and different trading partners in a many-to-many environment. Implementation time frames are shorter and completed with much less effort. With the help of agile messaging tools that are designed to meet these new requirements, configurable interoperability enables the implementation of business relationships in near real-time. What once took hours now only takes minutes or even seconds with the end users do it all by themselves. Thus, the increased benefit for the added configurability is not as a matter of degree, but one of orders-of-magnitude.
Object Technology Today’s rules-based object-oriented architecture can enable supply chain players to divide the business logic between the applications and the ‘connecting’ messages just as in human conversation. With help from JAVA, the object-oriented programming language, users now have a mobile code system. This means that self-contained object-based messages (executable code and the business content and intent that goes with it) become portable, reusable and disposable.
When put in the CORBA or DCOM standards formats for distributed object computing, the JAVA objects can be dynamically loaded and executed by different applications in different processing environments. Messaging applications can be written once and then reused anywhere. When coupled with Web technology, messages can be used to access almost any application, anywhere.
Thus, achieving ‘mutual application behavior’ has become a reality - even for the most disparate systems. Properly designed systems can be configured in minutes and hours, a process that once took weeks and months. Legacy hard-code custom programming, conversion tables, and centralized processing can be replaced with business object and rules-based distributed environments. As a consequence, the control of the business process can now be placed in the hands of those in the front lines -- those who make the everyday decisions -- not programmers and the MIS department.
Electronic Commerce Semantic messaging can not do it all by itself. Although it can take care of the content and intent, there is still the requirement for message delivery from one location to another. This is the responsibility of Electronic Commerce or EC.
EC is what enables ‘paperless’ business, a requirement for existence in today’s fast-paced world. Through a series of agreed upon standards and protocols, EC resolves technical differences, crosses international communications boundaries, and overcomes other barriers to the easy and ubiquitous interchange of information and data.
EC comes in a variety of forms ranging from the highly structured Electronic Data Interchange (EDI) for direct transfer from application-to-application, to the free form e-mail for human-to-human communications. Somewhere in between is the Internet, FAX, point-of-sale, and direct links for programmable logical control devices such a bar-code scanners and label printers.
VI: Making configurable interoperability happen: sMG’s and ECM working together
Distributing or ‘splitting’ of the logic is the essence of interoperability. With help from Semantic Messaging Gateways (SMGs) and the Electronic Commerce Manager (ECM), users are in control as they provide their instructions to ‘run’ their businesses their way. If business relationships change, they only need to change the existing instructions or prove new ones. This is in direct contrast with traditional code-based architectures where users are controlled by their business systems -- by the coded architecture permits the delivery of information only according to ‘rules’ of the application.
The logic is shared between the core application and messaging functions with the SMGs managing the application logic and the ECM doing the same for the business logic. Working together, the SMGs and ECM make the ‘decisions’ in a rules and instructions environment that enables the configuring and processes of business information in and out of the host application. Stated another way, ECM is the advocate for the business interests and the SMGs are the advocates for the application’s interests. Working together they resolve their difference and make the path between the two seamless and configurable.
Semantic Messaging Gateways
Semantic Message Gateways (SMGs) are an interface for passing information to and from BPCS Client/Server and some external application. Instead of directly attaching to a BPCS database and querying or updating it, an external application attaches to an SMG that represents a business object - a person, place event, documents, business process or concept. Typical examples of business objects are customer, product, purchase order, and payment. Once the connection has been made, the SMG then manages what tables to query and what BPCS Client/Server system components should be launched and provides the information in a semantically complete and self defining format. This avoids the complexity of knowing the specific technical details such as table and column names that should be accessed or which programs should be launched. Changes that inevitably occur to BPCS Client/Server will not impact the interface to the external application. Consequently, SMGs provide one of the enabling technologies and infrastructures that will satisfy today’s business needs for agility, configurability, and quick response to changing business process needs with the shortest time to realize a benefit.
SMGs use a language-like way of communication, called semantic messaging, to send requests or orders to and from the host application. Using semantic messaging reduces the brittleness often associated with traditional interfaces, reduces the time and impact analysis associated with determining what needs to be done, and simplifies what has to be done to implement an interface.
Also, because SMGs represent the behaviors and characteristics of business-recognizable things such as orders, warehouses, and invoices, they also reduce errors introduced when business requirements must be translated into non-business things called programs and databases.
SMGs are Business Objects (not programs or databases). Under the covers, SMGs are implementations organized to represent business objects. In so doing, they are exceptionally well suited to naturally representing those things businesses must manipulate. The closer system components can come to representing either the real assets of a business such as Items, warehouses, or locations, or the products of business activity such as customer orders or customer invoices, the easier it will be to support and represent the every day process of conducting business. On the other hand, programs, databases, interfaces, files, APIs, and even to some extent, screens, are technical compromises that obscure and sometimes hide business meaning.
SMGs are Messages (not APIs). Traditional interfaces or APIs between system components are data-centric and very brittle. They are also limited to a pre-defined collection of contexts usually represented by some kind of transaction code. Both the sender and receiver have to share quite a bit of information about the interface and agree on it all before the interface can be used.
Semantic Messaging eliminates the problems with traditional APIs and other types of data-centric interface techniques. Semantic Messaging works on the principle that the message should contain all the information necessary to interpret what it means and what context it represents, just like a conversation between two people. But like a conversation, the only thing that has to be agreed to up front is the language and the dictionary of terms that the two programs will share.
When using Semantic Messaging, change can be applied more quickly because the bindings between system components are looser. Receiving components are not bound to keep up with changes the generating components incorporate into the message; they just ignore additional information in the message until they are ready to deal with it.
SMGs are the key to interoperability. Using SMGs assures that changes that inevitably occur to the host application or to external applications do not affect each other. In fact, as long as SMGs are used to implement business processes from external and the host application components, then change can be applied without worrying about the impact on other system components using SMGs.
The Electronic Commerce Manager
The Electronic Commerce Manager (ECM) roles is to manage information that is transmitted between the host application and user trading partners. ECM creates a seamless connection that is capable of resolving differences between internal the host application and external business information. ECM enables the transparent exchange of business data such as Electronic Data Interchange (EDI), Internet, FAX, and e-mail without the need for in-depth knowledge of the host application, the standards, custom programming, or manual intervention.
ECM’s Windows™ graphical interface can be used to configure and manage trading partner specific information including data which is not part of the host application process. Additionally, ECM also provides for prioritization of transaction processing, archiving activity history, and validating trading partner identities and contact information. ECM has an extensive trading partner classification model including both inter and intra-enterprise options such as customer, vendor, bank, carrier, warehouse, and company.
ECM is event driven. That means end-to-end communication controls can be automated. The ‘feeding’ of message to the host application can be managed - high priority messages can be moved ahead of those with lower priority, time consuming high volume messages can be scheduled for off-peak times, etc. (The Semantic Message Gateways (SMG) have no mechanism to perform this function.)
ECM replaces the need for API’s and associated hard-code with instructions based on the host application, EDI and other messaging standards, and trading partner business rules. Creating new instructions only requires the selection of the right rules. Making a change only requires a change in the rules.
ECM cannot act alone but must have help from the host application and the external interchange software. This is where the Semantic Messaging Gateway (SMG) and EC translation software or the Internet play an important role.
The ECM and the SMGs are integral parts that work together to enable the interoperable interchange of data with any external source. The process works (in either direction) like this...
ECM can provide the end-to-end rules-based or semantic integration because ...
VI. Summary
Businesses are losing their stand-alone identity. They are no longer the ‘center of their own universe’ but part of a much larger one that extends around the world. To participate in this emerging virtual world, businesses are learning to become agile, flexible, and dynamic. They are learning how to interoperate with their customers and suppliers as they strive to meet a wider variety of constantly changing requirements and business needs. They are demanding more and better products and services to run their businesses. They have raised the ‘functionality’ bar.
It is becoming increasingly difficult (if not impossible) to provide all manners of functionality from a single product. There is no ‘one size fits all.’ There is no ‘one way’ to do business. As much as we would like to think that any host application can do it all in a way that is agreeable to everyone, to do so would be unrealistic, impractical, and very expensive. The answer, then, is a combination of a robust host application and a repository of complementary external products, technologies and tools -- all working together to achieve the best in configurable interoperability in an environment that can be individualized to meet the needs of a particular user.
To do this, to achieve this state, to ‘get there,’ we must replace indentured functionality with configurable messaging!
Henry Ford once said about his Model T that the buyer could have any color he wanted just as long as it was black. And so it is with code based applications where functionality is only limited by the number of programmers and the available time to deliver and test code. Need some new functionality? Just change a program or add a little code. Sounds good but before you know it, your application has grown to unmanageable proportions and you have become its indentured slave. Sure, you can do anything you want, but only to the extent the program logic lets you do it.
The hold that code-based applications have on their owners, although not obvious, is quite remarkable if not insidious. It is like cooking a frog. Throw a frog in boiling water and it will jump out. Place it in the water first and then turn up the heat and before the frog realizes what is happening, it is too late. It is the same with owners and users of code based applications.
On the other hand, with configurable messaging, you can have it your way and keep it that way. With the meaning in the message, the functional requirements for a particular instance or event comes with the message, ‘stays’ around only long enough to do the job, and is discarded to make room for the next message for the next instance or event. It as with human conversation, the message becomes portable, reusable, and disposable. We listen to what we need to complete the instance, remember what we want, and discard the rest. Configurable messaging means that programs do not grow or need to be changed. The only thing that changes is the data base which is supposed to change.
The bottom line is the bottom line. GartnerGroup states that world-class enterprises will enjoy an advantage of 8 to 10 percent of annual revenue. The catch is that is will take configurable interoperability and messaging to become world-class.