Delivering Service: Managing Strategically in a Tactical World
1815 S. Meyers RoadOakbrook Terrace, IL 60181
Phones: 800-442-6861 (U.S. and Canada)
(630) 620-5000 (Worldwide)
Fax: (630) 691-0710
E-mail: info@platinum.com
URL: www.platinum.com


The unprecedented growth in client server distributed systems and new technologies provides a significant challenge to IT managers. How do we move from tactical fire fighting to strategic management of the enterprise? What are the key strategic decisions, which must be faced in order to begin making more efficient and effective use of IT resources? Many IT managers simply go from "fire drill to fire drill" barely having time to consider the key factors that are causing them to be so reactive...let alone give them the opportunity to become proactive about performance, availability and understanding how IT resources are used within the enterprise environment. Delivering high levels of service and moving from tactical to strategic enterprise management is not a simple task. It is, however, quickly becoming a competitive differentiator for many companies and a critical requirement to building a managed enterprise environment and improving the IT infrastructure.
Although highly distributed client server environments have provided increased flexibility and have enabled managers to lower the cost of computing in many areas, client server systems have also significantly increased the complexity of managing and expanding the enterprise. The increasing complexity is compounded by a number of other challenges, including:
One of the most significant problems continues to be a lack of knowledgeable DBA resources, especially in the area of managing Oracle databases and applications. This skills crisis continues to worsen, necessitating many IT managers to search for tools to reduce the number of DBAs required to maintain the systems and automate more manual processes in order to do more with less staff. Not surprisingly, a recent commerce statistic estimated that there are over 400,000 IT jobs open due to the lack of qualified candidates. As the gap continues to increase, IT managers are looking for tools with built-in intelligence and inter-automation capabilities that can simplify the process of managing a highly distributed environment.
For most IT organizations today, around-the-clock management is not just a goal, it’s a requirement. And global companies are often faced with a shrinking maintenance window of minutes or hours, instead of days. If needed work cannot be completed, mission critical systems go down and can have a large financial impact to the business. As these time windows continue to shrink, IT managers are forced to prioritize database, server and network maintenance and enhancements, completing only the most critical tasks. Companies that fail to put the infrastructure in place prior to running production systems usually also fail to allocate sufficient time and resources to set up a proactive monitoring and management environment. The result is that they often experience the pain of unpleasant surprises like downtime, excessive fragmentation, memory, and poorly running SQL. There is insufficient time to fix problems and prevent them from reoccurring in the future.
As a company’s business expands, what will the growth rate of the support staff need to be? Is it possible to delay or defer hiring by deploying tools designed to automate repetitive tasks? James Martin in his book, "Cybercorp" said, "Corporations cannot design and maintain the complex integration of systems that is needed unless computers themselves are used for that task. "The automation of automation is essential. 1". Automation is one of the most significant reasons that companies have embarked on framework initiatives to integrate disparate technologies or have tried, with limited success, to integrate tools on their own.
IT managers face constant pressures to firefight and solve problems reactively. Workloads continue to increase without adequate IT staffing to expand the infrastructure. This causes an increasing number of operational problems and taxes the help desk. And as more and more companies approach new technologies like the Intranet and Internet, existing client server models and capacity plans fall apart. Managers can no longer gauge the impact of new applications on IT resources, so they use their best judgement to over-engineer networks, hoping to guarantee fast response time and adequate I/O ratios. Many problems also occur because data about the operation of the enterprise is not shared collaboratively so that staff can work together to solve problems.
In the midst of all of this change, financial managers are enforcing new policies, which force IT to quantify and cost-justify all technology investments to clear business objectives. IT Managers scramble to develop cost justifications and estimate capacities to support the budget approval process typically making a variety of assumptions that are sometimes incorrect -- and more often understated -- based on the tasks at hand.
While the challenges continue to compound, technology continues to evolve and push toward real automation of the enterprise. Creating a managed, proactive environment, although difficult, can be accomplished through good planning, knowledge of critical business processes and implementation of software tools which allow you manage and improve the IT infrastructure.
The Performance Perspective
One of the most important first steps in developing a managed environment is managing application and systems performance. Many IT managers make the mistake of approaching performance management from only a singular, checklist type of approach without really considering all the aspects of performance that relate to a specific application or business process. Chris Loosley, co-author of the book, "High Performance Client Server," 2 suggests that many companies need to realize that the scope of performance needs to be expanded to consider the infrastructure, the business process, application flow, and business impact, as well as the hardware and software environment.
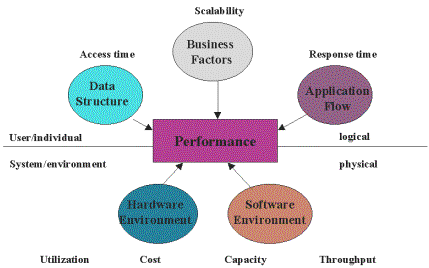
Diagram 1: High-Performance Client/Server
Loosely suggests that, "At the most fundamental level, almost everything we need to know about performance of any computer system can be described in terms of five simple concepts,"3 which must be understood, including:
According to Loosley, workload, response times and throughput represent external sources that describe the observed performance. He says, "Resource utilization and resource service times describe how the computer system behaves internally, providing the technical explanation for the externally observed performance characteristics."3 This concept for managing performance is interesting because it takes a more holistic approach to managing the process of performance and considers not only the typical infrastructure metrics, but other factors that have a direct impact on the ability of the company to deliver service and manage the business process. The first step in delivering service for many IT managers is in clearly defining the monitoring environment and in implementing best of class tools to avoid downtime, slow response time, and other problems. PLATINUM’s ProVision suite of tools provides a valuable approach because it actually integrates the tools to make them inter-operate, automate repetitive processes, and take corrective actions based on correlated events that occur in the environment.
Why the Focus on Service Level Management (SLM)?
Hurwitz Group defines service level management as "a process that includes establishing service level objectives and expectations, creating service level agreements (SLA’s), monitoring service levels, collecting and analyzing data, and establishing user feedback and escalation procedures". 4
The renewed focus on service levels has been driven by a number of issues. First, key industry analysts all agree that there is a renewed interest in service level management because of the increasingly competitive environment. Many companies are looking toward IT to establish measurable service levels with the user community not only to identify which key services are delivered to users, but also to measure and document how well IT organizations are delivering the demanded services requested by the user community. In fact, many user communities are demanding that SLM measures be written in contracts to guarantee systems availability, reliability and response time. Financial incentives or disincentives are even used occasionally to encourage compliance.
Second, senior IT managers are asking for SLM measures because they want to manage by exception and make sure that their IT organization is delivering adequate service to the user community. The only way to clearly measure the impact is to put in some control points. The third reason for SLM’s increasing popularity is that the user community has banded together to force IT to deliver the services they demand and SLM allows users to more closely monitor not only the level of service delivered, but also how often violations occur.
Companies just beginning to establish service level management within their organization need to keep in mind that defining measures of service is the first critical step. SLM requires a coordinated effort among people, processes, organizations, and technologies to be able to guarantee that service levels are delivered. Many companies make the mistake of trying to measure a large volume of metrics from the beginning. They often end up dissatisfied with their ability to track and measure the volume of information needed to monitor performance. In fact, if you are just getting started, most consultants will suggest that you limit the scope of your initial SLM metrics until the process of monitoring, measuring, and violation resolution is stable.
Over the last year, a dozen or so service level management tools have entered the marketplace and provided partial solutions targeted at market niches. From the applications perspective, companies like Micromuse, InfoVista, NextPoint Networks, Avesta, Quallaby, Concord, HP, and others have developed tools that typically access MIB , logfile, and other information sources to quantify and evaluate some of the common SLM measurements. The reason SLM continues to be an effective and necessary strategy for many companies is because it is built on the concept that IT Infrastructure exists to support the business users. A well orchestrated SLM implementation can yield significant financial and operational benefits because these measurements are typically put in place for mission critical business processes – areas where improvements can have the highest financial impact.
Clearly Defining Service Level Agreements
Hurwitz Group, in their research report on the Evolution of SLAs identified that "Service is fast becoming a competitive differentiator in many industries. Because of this, many companies are turning to service level agreements (SLAs) that guarantee that a service provider will provide a certain level of service to its customers."5 Highly distributed, complex client server environments have increased the need for some measurement standards to ensure availability, reliability, and high levels of performance. Users, demanding a yardstick from IT, have led the way in establishing contracts with their data centers to ensure they effectively and proactively manage service delivery. In addition, users are demanding and specifying how quickly problems must be resolved and standardizing a process to that end. This has led to the establishment of Service Level Agreements. SLAs are typically written contracts between IT managers and users specifying specific measurable performance in areas like application availability, response time, reliability, application and process health, transaction SQL analysis, trouble ticketing, and others.
One of the challenges in writing a meaningful SLA is ensuring that the correct performance statistics are selected and that they clearly provide meaningful and measurable information. What’s the process for creating and maintaining a service level agreement? Below is a recommended seven-step iterative process for developing, maintaining and measuring service level agreements.
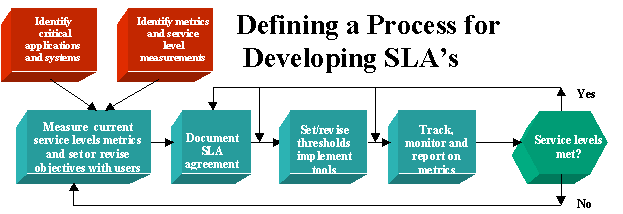
Steps to Developing Service Level Agreements
Step 1: Identify mission critical applications and systems which need to be monitored.
Step 2: Identify Metrics and service levels required.
Step 3: Measure current service levels and establish objectives.
Step 4: Document and formalize the service level agreement documents.
Step 5: Set and refine thresholds within tools for measuring service levels achieved.
Step 6: Track, monitor, and report on the actual metrics versus the SLA measurements.
Step 7: If the service levels are met, continue to monitor and report compliance. If the service levels are not met, evaluate why this occurred and meet with users to either adjust metrics or take other corrective actions.
As more and more companies struggle to find ways to define and provide better service to users, customers, and senior management, it is important to understand how tools can help to monitor and measure performance and run operations,. We also need to understand the impact of IT resource usage and establish infrastructure metric management within the enterprise.
If it is true that the role of IT has changed from a cost center to a profit center whose product is those services demanded by the user community, then how do you best measure the real value of service from a business perspective? While typical return on investment (ROI) calculations and formulas provide the basic argument for justifying IT expenditures, they often miss some of the key measurements of the effectiveness of that service. In fact, a 1997 Computer Economics Report estimates that approximately 75-80 percent of IT investment -- whether they are for data centers or Web pages -- offer no easily calculated business value. In fact, many companies cannot track money spent on databases, servers, IT salaries, or maintenance to specific projects or initiatives. A lot of CIOs and IT managers are justifying budgets based on tracking a new class of service measures and metrics that link to their business. While service level management provides a great improvement because it seeks to quantify service performance at least to some extent, most first generation SLAs focused on infrastructure kinds of metrics (availability, performance and reliability). Meta Group recommends second generation SLAs use a balanced scorecard approach 6, which integrates a variety of metrics infrastructure, customer satisfaction, application and quality metrics in defining service level agreements. The balanced scorecard quantifies more business process and customer satisfaction oriented metrics to provide a more complete view of the overall service level component.
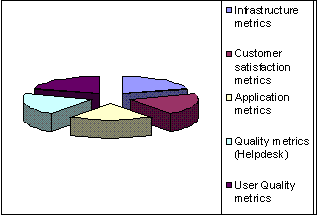
Diagram 3:Balanced Scorecard Approach, Meta Group, 1998.
Defining and implementing service level agreements alone fall short on addressing some of the real issues that hold companies back from becoming strategic. Meta Group in an April 1998 research note, recommended that a "fundamental change in perspective and in the process of delivering services to end users must occur."7 They estimate that 80% of IT organizations are still organized by technology capabilities (e.g., networking, applications, help desk), instead of by areas of business impact. According to Meta Group, "during the next three years, most organizations will implement second generation SLAs and application subscription SLAs focused on business impact, rather than on technology delivery".8 Meta Group further suggest evaluating a number of services related to application subscriptions, including areas such as:
Rather than focusing on a discipline area, application subscriptions focus on measuring and managing the elements that comprise the application.
Avoiding the Common Mistakes
While the goal of automating processes and defining SLAs to measure service moves companies ahead in starting to examine quantitatively how their service processes are performing, top industry analysts feel companies sometimes make avoidable mistakes that often account for much of the failure of IT initiatives. First, in some companies there is clearly a mismatch of the technology tool capabilities when compared to the business process. Companies often purchase tools based on a checklist approach alone with really identifying what they need those tools to accomplish. A second common mistake is the absence of a clearly defined business process. It’s difficult or impossible to deliver service levels or define measurable SLAs when there is not a clear understanding of the business process and its requirements. A third mistake made by most companies is to align technology based on domains and platforms instead of processes. In most cases, technology alignment discourages communication between groups and reduces their ability to solve business and technical problems collaboratively.
The pressure for return on investment (ROI) has fostered a push toward decreasing project timetables and gets [something] up and running more quickly in order to get a payback on your investment. Meta Group has defined this as "mean time to value," 9 or how quickly payback can be derived from the IT investment. Managers are focused on how quickly tools can be installed, implemented and functional for the IT investment. It’s important to note that regardless of the tools selected, resources assigned, or plans made, IT managers who fail to clearly identify and match process to tool functionality make mistakes that could ultimately cause their project to fail.
Managing By the Metrics
Proactive management of infrastructure metrics is only one component of many required to architect a well managed environment. While second generation SLAs and metrics continue to evolve, it’s important to keep in mind that there is a number of defined measures of service that you might want to consider. Below is a listing of some commonly used measurements:
Examples of Measures of Service
A. Availability -Node Up, Node down -Process running, Process failed -Thresholds exceeded -Ratio of how much time system is usable -Network metrics-LAN, WAN, Failures -Email states and thresholds B. Reliability/Stability -How much workload is processed -Evaluate bandwidth utilization -# of interruptions or outages in "x" time period
C. Response Time -Time required to process a single unit of work -End to end transaction response time -Inbound and outbound web traffic response time -Application processing speed -Time to access and view data -Average transaction response time D. Application and Process Health -Application or process up or down -Data flow measurement -Heartbeat monitoring and alarming -Application processing E. Problem Tracking/Trouble Ticketing -Trouble Ticket tracking -Trending of problems by type and frequency --Number of calls per "x" time period -Average time to close a trouble ticket -Abandoned calls vs. call response time |
F. Transaction SQL Analysis -Runaway processes per "x" time period -Drill down –heavy transaction users G. Workload Management -Balancing workloads across multiple servers -Impact of new applications on workload -Average throughput on a transaction basis -Utilization -- amount of workload processed H. Quality of Service -Number of calls versus problems -Average time to solve and close trouble ticket -# of re-occurrence of problems -% of open trouble tickets closed within "x" period of time -Modifications/changes processed correctly I. Customer Satisfaction -Application impact on business objectives -Help Desk support speed -Satisfaction level with overall application performance I. Usage -Web Usage (Inbound & Outbound Hits) -CPU Utilization vs Server Utilization -% Capacity available trended over time -% Bandwidth utilized by protocol -% Memory available vs server usage -#Deadlocks or record locks per database -# of SQL statements running longer than "x" time period -# of transactions vs # of successfully completed transactions |
Becoming more Strategic
Managing strategically in a tactical world means improving the decision process and how it is implemented in the enterprise environment. Issues such as how all IT resources are managed, how the IT Infrastructure is expanded, what level of service is delivered to users and how quickly problems or violations are resolved. These are the decisions that will have the most significant impact on improving efficiency and effectiveness of the IT operations and can move a company ahead to gain competitive advantage by leveraging IT resources and technology. One of the most important first steps is evaluating the environment and developing a plan for how and what service applications and user groups required to manage the business. Problems that occur within mission critical systems obviously will have a greater impact on the company than other non-production systems.
Recommendations
Below are a number of recommendations for building a more proactive, manageable enterprise environment:
Many companies install production systems and tools prior to understanding what really needs to be managed within the environment. As a result, the lack of DBAs, the need for lights out monitoring and other challenges prevent IT organizations from becoming more proactive. Companies typically select and implement three to five major IT initiatives per year. Over the course of 5 years that translates into fifteen to twenty five applications that need to be managed, maintained and updated. If an infrastructure plan is not established ahead of time, the compounded effect of more and more initiatives drives the manageability problem from being complex to manage, to being impossible.
The easiest way to reduce costs is to automate repetitive tasks within the environment. The skills crisis has prompted many IT managers to look to tool companies like PLATINUM technology to provide database and systems management tools to not only automate tasks, but to alert users when thresholds are exceeded and in some cases, take corrective actions before major problems occur. In one company, a DBA was able to reduce his workload by over 42 percent and actually defer hiring an additional DBA to manage the environment. Tools also provide consistency in the way problems are identified and resolved within the environment.
As service levels are defined, natural control points will be established and measured like %CPU usage, # of SLA violations, % availability, # transactions processed vs response time, and other measures. These control points become very valuable to senior IT management, who look to provide quantifiable measures of service back to the business unit managers and the CEO. These control points can also be used to demonstrate recurring problems in the environment that might require additional resources to solve over the long term.
Service level management and service level agreements can be used to ensure not only that adequate service levels are delivered, but to document and surface recurring operational problems that might not be identified without SLM in place. For example, if a new order entry application with a web interface is deployed within the environment, initial usage might be limited until customers become aware that orders can be entered on the Web. Once the application is more widely used, systems resources become taxed. If a service level for a less-than-five-second transaction response time is in place, as SLA violations occur, managers are made aware that the server may no longer be able to handle the load of transactions while meeting the SLA requirement.
One of the most difficult jobs IT managers face is justifying the benefits of the service they provide to the user community. By implementing service level measures and service level agreements with the users, both groups determine what acceptable service is. Once these measures are in place, business unit managers and IT can work together to refine and improve processes and lower costs. SLM exception reports can be used not only to focus on problem areas in service, but also ultimately, to quantify the value of IT to the enterprise.
Summary
The real impact of measuring and managing service levels has yet to be realized by many organizations. In fact Yankee Group estimates that less than 25 percent of Fortune 1000 companies interviewed met their service levels. Most companies today, are still in the initial adoption stages of evaluating which infrastructure metrics to measure, determining service level requirements and building a process for measuring those service levels against specific objectives. As SLM technology becomes more sophisticated and the infrastructure is better established, IT managers will be able to shift focus toward "exception based management", implement tools to automate the enterprise and this will allow them to concentrate on leveraging technology to gain a competitive advantage. This shift toward more proactive IT management and delivering higher levels of service will also finally allow the IT organization to have a more strategic impact on business operations and profitability.
Footnotes:
1
Martin, James, "Cybercorp", American Management Society, 1996, pg. 26.2
Loosley, Chris and Douglas, Frank, "High Performance Client Server, Wiley Computer Publishing, 1998, pg. 44.3
Loosley, Chris and Douglas, Frank, "High Performance Client Server", Wiley Computer Publishing, 1998, pg. 44.4
"Evolution of SLA", Hurwitz Group Research Bulletin, Dec. 31, 1997, pg. 1.5
"Evolution of SLA", Hurwitz Group Research Bulletin, Dec. 31, 1997, pg. 1.6
"SLM: The StopWatch is Running", Meta Group Inc., Research Bulletin, SSMS Delta 666, January 1998, pg. 1.7
"From MTSP to SLA: Part 2- Application Subscriptions", Meta Group Research Bulletin, File 687, April 1998 pg. 1.8
"From MTSP to SLA: Part 2- Application Subscriptions", Meta Group Research Bulletin, File 687, April 1998 pg. 1.9
"SLM: The StopWatch is Running", Meta Group Inc., Research Bulletin, SSMS Delta 666, January 1998, p. 2.To obtain additional information, please contact PLATINUM technology, inc.,
© 1998 by PLATINUM technology, inc. All rights reserved. The PLATINUM products referenced in this document are trademarks of PLATINUM technology, inc. and its subsidiaries.