 4 waves of ERP engineering in the 90s
4 waves of ERP engineering in the 90s
Vice President,
Product Marketing
TopTier Software
6203 San Ignacio Ave. Suite # 240
San Jose, CA 95119
Phone: (408) 360-1700 x233
Fax: (408) 360-1703
Email: roger@toptiersw.com
Introduction
Today’s ever-changing business landscape is creating flatter, more dispersed organizational structures, placing even more critical decision-making demands on corporate knowledge workers and end users. While these corporate end-users increasingly seek easier access to more detailed sources of information, existing IT products’ data access and data integration capabilities simply have not kept pace with the complexity of users’ needs. At the same time, the emergence of the Internet and Web-based technologies has improved certain aspects of data navigation and integration for enterprises and individuals by simplifying the user interface and allowing more ubiquitous network architectures. The use of hypertext for accessing unstructured Internet data has proven to be a key factor in the speed of discovery and the rate of comprehension for Internet users. Unfortunately, there hasn’t been an analogous solution for accessing and interacting with the vast stores of business critical, structured data residing in ERP systems, corporate databases and repositories. Managing the explosion of databases and integrating them with ERP systems and legacy applications has become a top priority for IS groups. This paper proposes that new internet-based approaches based on Confederated Component Models and HyperRelational Systems can help IS groups extend ERP solutions by linking them to proprietary databases as well as other pre-packaged and customized applications.
4 waves of ERP engineering in the 90s
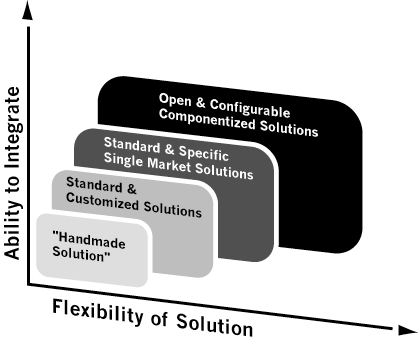
Their have been 4 waves of ERP engineering in the ‘90s. First-wave ERP systems were rudimentary frameworks of functionality requiring large on-going investments in consulting services. Consultants used these frameworks as a starting point to develop handmade "one off" solutions that were tough to integrate with legacy applications and difficult to extend as business conditions changed. In the second wave, ERP vendors took what they learned from consulting engagements and consolidated commonly requested functionality into basic or "standard" modules. The approach was to install the "standard" module and customize it until it became the customer’s "new legacy". Second-wave solutions were built on well defined "buckets" of code and were somewhat easier to integrate with existing applications and more flexible. The third wave has yielded complete suites of tightly synchronized proprietary applications, delivered as single "monolithic" products. Because of size and complexity, ERP vendors deliver major releases every 18-20 months and minor releases every 6 months. Releases can be customized using extensions for specific vertical markets like process manufacturing and aerospace and defense. The fourth wave of ERP is just beginning. It is the move to "componentized" product suites that are more flexible, configurable and open for easier integration of non-proprietary best-of- breed applications. This is the next competitive battlefield for the big ERP vendors.
Enterprise Information Systems: A Situation Analysis
Today’s Enterprise Information Systems are commonly an amalgam of disconnected data sources accessible by various unrelated applications. In fact, the average number of servers in Fortune 1000 corporations reached 300 last year, and this average keeps growing at an alarming speed. Those 300 data sources represent the fragmented islands of information that each corporation’s users need to navigate and cross daily in order to work productively. Yet no bridges connect these islands, and no maps assist users in finding their daily route.
Roots and Reasons
Why are these islands of information disconnected? Typically, an organization’s existing applications and data sources were designed and built by different generations of programmers rarely present in the enterprise IS department today. Data models commonly change numerous times to reflect the changing nature of the business they were modeling. Applications also grow over the years, reaching maturity only after several years of upgrades, modifications, and fixes have been applied to the original work. To further complicate the situation, custom applications built in-house may continue operating for years, while packaged applications are becoming the backbone of most enterprises.
Effects on Users and Productivity
Today, the cost of maintaining and improving applications is growing exponentially, while the benefit from these improvements grows linearly at best. On an enterprise level, this reversed economy of scale typically reaches a point where most of the corporate IS budget is devoted to maintaining existing IS infrastructure, with little if any money left for improvements.
Users, on the other hand, are required to become increasingly proficient in various aspects of their business. Yet today’s knowledge workers cannot work with a single information system to resolve any and every issue they face during normal business operations. While common problems should be resolved through the use of a single application with a single interface, they regularly require multiple systems—and at times multiple employees. This increases the cost of training. Because when each application deploys a different user interface and a different application design, users must become familiar with those conventions before they are free to access the data that’s portrayed. There are also significant business costs, because data that is stored but practically inaccessible cannot be used to maintain efficient business operations.
Limitations of a Web Solution
Recently, a strong push for the introduction of web technology into the enterprise established another layer of user interface on top of existing C/S solutions. This "Intranet" approach created a distributed set of pages and code that were supposed to unify accessibility to information across the enterprise. Unfortunately the metaphor of the web, "hypertext," differs drastically from the foundation of client-server computing. Hypertext is based on a model in which authors link pages with physical links, and users browse these author-controlled links. Relational databases, on which current applications are based, deploy a relational model that associates records through meta-data, and a user should be free to follow these relations in run-time rather than design-time.
The mismatch between these two metaphors is currently being bridged through tedious manual processes, and the resulting web-based applications inhibit users from accessing their data in associative ways. In this situation, users suffer from the limitations of both models, instead of leveraging their strengths. This conflict is very similar in magnitude and effect to the impedance mismatch between object orientation and relational model, which the computer industry has been resolving in recent years. This time the mismatch reveals itself at the client tier and not the storage tier.
A New Vision
The latest industry vision of Digital Nervous System (DNS) proposes a model that enables every user inside and outside the enterprise to access every element of the corporate information space. For this vision to be realized, the enterprise must virtually connect all its systems—and provide a unified access model to the connected enterprise virtual backbone. HyperRelational systems built on confederated component models are the first real incarnation of the DNS vision.
Increasing Object Orientation Value
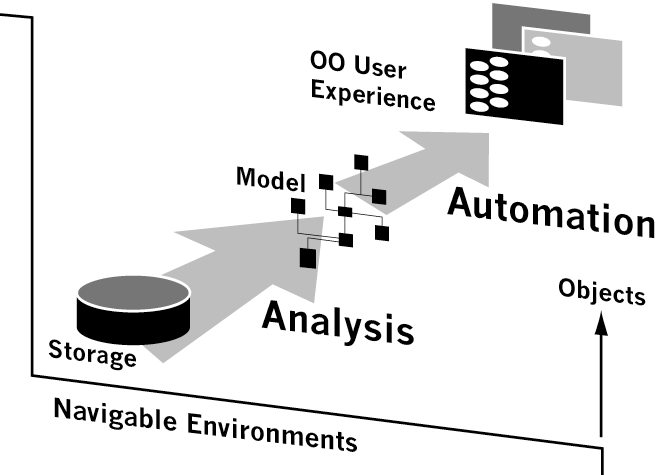
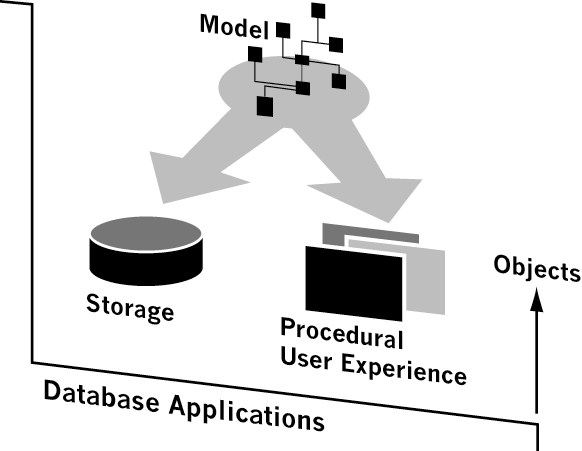
With today’s Object Oriented (OO) approach to software design, organizations spend months developing the specifications for the IS Object Model, trying to ensure compliance with new business models. These models are usually mapped into a Relational Storage model and a Procedural User Experience. Impedance mismatches on both ends of the spectrum create problems that absorb the majority of development time and resources. Long term, the mismatch requires developers to repeat their efforts on every change in the model, which counteracts the OO benefits of reusability, encapsulation, and inheritance.
HyperRelational systems eliminate the impedance mismatch, and it reverses the conventional development process by building an Object Model from the Storage Model and building a User Experience from that model. The resulting system provides the first true OO User Experience available in the market today, incorporating all the benefits of OO at the end-user tier. Every HyperRelational system presents more value for the user than the underlying model, without the associated cost. This process is also the first to allow ongoing changes in the model, without interfering with the user’s view of the system or the cost associated with the model.
HyperRelational Systems
HyperRelational Systems provide three primary benefits, which we will explore in the following sections:
Integration
Using confederated components, HyperRelational systems are implemented on top of existing datasources and applications, without any need to change the core information infrastructure. Each HyperRelational system stands on its own. Yet by correlating the underlying confederated component models, a web of connected object models is created. For the end user, this web of models creates the experience of tightly coupled systems, fully integrated into a single client tier. At the same time, other users can continue working on those applications and models—using existing applications—or combine them into other HyperRelational webs.
This loose-coupling approach allows the enterprise to integrate internal, external, and web-based systems in an incremental fashion. As each additional system is introduced into this HyperRelational web, the scope and value of the system grows exponentially. The same incremental process can be applied across multiple companies, which can synchronize their models to create true value-chain integration.
Navigation
HyperRelational Navigation provides the first method of navigating through large collections of structured and unstructured information that is truly controlled by the end user. With this "Point-of-View Navigation," (POVn) users can navigate from any entity in their model to any related entity in their model—or any correlated model. This versatility is achieved by using the "Drag-and-Relate" user interface gesture. Navigation can occur between a broad spectrum of entities, which can represent classes, instances, logical and physical subclasses, or reports—as well as many other entities that can be described with this user experience. The user interacts and creates components on the screen, directing the navigation every step of the way. Although users are unencumbered by predetermined paths, they are not aimlessly wandering, since the underlying model dictates the relationship between entities.
Simplification
By extending the navigation model of the web, HyperRelational systems simplify access to large, complex enterprise information systems. The simplicity of the web is based on its "single-predicate language." The only concept the user is required to comprehend is: "Click on the blue underlined link." HyperRelational systems build on that predicate by adding the ability to drag-and-relate those links. For the first time, users can view and interact with "tactile" elements representing objects. Once they add the drag-and-drop gesture to their interface vocabulary, users are ready to navigate in any direction and on top of any system.
The navigation actually follows the relations dictated by the underlying models, which enables users to "customize" their system by combining elements, according to their immediate needs. In effect, novice users become power users without the need to train them on complex IS tools, since their simple drag-and-drop gestures bring about results that would have required special code tailoring in any other technology.
Results: Reduced "Time to Resolution."
By combining these three major benefits, HyperRelational systems deliver a drastic improvement in "time to resolution"—up to 80% average improvements once an organization’s information system becomes HyperRelational. This measurement is based on the time it takes a knowledge worker to resolve a typical business situation, compared to the time it takes to resolve the same situation using the current application interface.
How are these significant improvements achieved? By providing knowledge workers with the ability to simply navigate across their integrated information system, unencumbered by artificial boundaries of disconnected information systems, empowered by the ability to associatively navigate the inherent relationships in the model, all the time using a very simple information system through a web browser.
Economy of Application Development
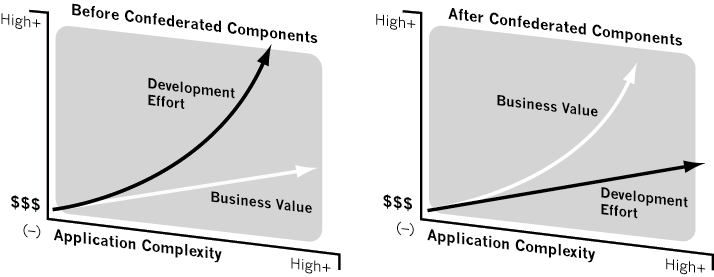
Conventional estimates for the cost of software development show that, as software grows larger, the cost of building the next version grows exponentially. Yet the benefit to users seems to grow only marginally. As a result, the long-term ROI of every release shrinks rapidly and reaches the point of negative return. Using confederated component technologies and methodologies, these economic rules change dramatically.
The confederated component approach allows developers to build applications one model at a time, yet the end result is a coherent Information System with no visible seams for the end user. With this approach, the application can be released in groups of components. Each component can function within the group, interact with existing components, and provide a new set of interaction capabilities for already existing components. The cost of creating components does not increase over time, since no extra work is required to create more links to components. With this model, the value of every new application increases exponentially. Specifically, it grows to the square of the number of components in the model (valued as the number of possible combinations the user can deploy). On the other hand, cost grows only linearly or sometimes declines as the developer becomes more expert in confederated component methodologies.
Confederated Components: A Systems Approach
Over the last fifteen years, object orientation has taken center stage in the computer systems world. The benefits of Object Orientation are well documented, showing dramatic improvements in every stage of a product’s lifecycle. It is now agreed that modeling techniques, which are the first step in software development cycle, have become object-centric across the whole industry. This fact drives every other step in the software development process towards Object Orientation.
Programming and Data Storage
Programming language trends in recent years have made object-oriented languages the de-facto standard in software development. From C++, Java, and even Object Cobol, the benefits of OO programming languages are evident in improved quality of software, shorter time of development, and reusability. Similarly, the latest storage model trends include object databases, ORBs, and Object-Relational hybrids, which have all led to a higher level of objectifying the way persistent data is stored and retrieved. More pragmatic approaches, such as Object-Relational mapping, allow enterprises to retain their relational engines, while providing OO access. These changes avoid impedance mismatches between the object-oriented model of the enterprise and its manifestation, whether it is to disk or into source-code.
The Lag at the End-User Level
The client tiers of today have not changed much since the early days of computing, and prevailing end-user experiences still follow a very procedural manifestation of any object concepts. Applications today still employ a menu-driven approach. Menu selections lead to interaction forms, which provide data access and management capabilities ("CRUD" model). This model creates a user-experience where screens are disconnected from one another and few if any predetermined wires exist between those forms. Manual or semi-automatic methods for creating forms, which are bound to underlying objects, still require users to understand rigid structures forced on them by application designers. In most cases, the benefits of object-orientation don’t surface to the end user, no matter how well designed or implemented the software may be.
Costs
This lag at the client level necessitates tremendous efforts for every revision of the software, in order to re-wire its interface to portray every change in the underlying model. As most other elements become object-oriented, the core cost of application development will soon become the creation and maintenance of the application’s user model.
The HyperRelational Solution
HyperRelational systems deploy a distinctively different approach. With this model, the basis of object-orientation can be applied to the client tier of an application, providing the benefits to the end user for the first time. Through the use of automated tools, HyperRelational systems build a new and expanded object model from the relational storage model. This allows for the use of legacy systems—and the continual upgrades of these models—with no cost hit. Those object models, in turn, automatically generate sets of components which are encapsulated representations of the underlying objects, yet they comply with the relations dictated by the model. Each of the components can stand and fully function on its own, yet together they create a confederation of components, representing the model to the end users.
Encapsulated component
Users and authors can enhance the confederation by creating more components, which represent such elements in the underlying model as instances, filters, queries, or presentation binding elements like graphs, reports, and forms. Any component can stand on its own, performing its default behaviors and inheriting any complementing traits from its parent components, based on the object model it follows.
In addition, any component representing elements from the model can feed into any presentation components, allowing the user to create powerful combinations on an ad hoc basis. Users can also share components with peers over the network. When such components are deployed in another user’s environment, they inherent the new operating environment’s rules, state, and limitations. In this way, a shared component still adheres to each user’s security limitations, as well as any filters and data collection it may be running against.
Correlation of Confederations
Finally, this confederated approach allows for the extremely powerful ability to combine multiple confederations sitting on top of multiple object models. The correlation of object models creates a superstructure containing every component in each of the confederations. This superset adheres to the rules of the confederated model. With this structure, every component in any of the models can interact with any component in any of the other correlated models. This creates an immediate loosely integrated solution spanning across multiple models, without any visible seams to the end user. As such, HyperRelational systems predicate that a combination of confederated components is a confederation in and of itself.
Object Web: A Distributed Component Model
There’s clear symmetry between the HyperRelational model and the web model, based on the concept of hypertext. Hypertext has existed for more than 30 years, prior to its current incarnation in the World Wide Web. Yet the last three years have demonstrated the most dramatic enhancements in the underlying concepts on which the web is built, a sudden leap that has inspired the phrase "development in web-weeks." The parallel between hypertext and HyperRelational concepts now allows HyperRelational systems to be introduced at a much more mature stage than was possible for early hypertext systems. The follow sections review the underlying concepts in this process.
Linked Objects
Conceptually, HyperRelational systems are built on sets of related object classes. This supports "point of view" navigation on top of a storage model, along the logical paths contained in the model itself. This structure is similar to the set of linked pages that constitute and create a web-site, but there’s an important difference. In the case of the web, one needs to create and replicate pages to scale a web site, but with HyperRelational systems, the navigation occurs on top of virtual pages driven from the data objects.
Linked Object Models
HyperRelational servers can point to other servers, creating virtual links among object models. It is sufficient to create one relation between one object in each model, in order to link any object in one model to any object in the other model. This is manifested by the fact that the user can drag any entity from one model to the other, and the system will automatically route and distribute the request between the linked servers. This is similar to the way one web server points to a page in another web server, thus creating a path for the user to cross from one web site to another. However, web links only enable navigation into the pointed page, and that link is not reversed or propagated to the rest of the site pages.
Encapsulation of Presentation Metaphors
HyperRelational systems provide a template adapter interface, which allows the author of the system to create bind information to new and different presentation mechanisms. In this way, HyperRelational systems can encapsulate any known element in today’s desktop and web universe by supporting a five-call API. Templates have been created for elements such as reports (Crystal reports by Seagate), Office Applications (Excel and Word by Microsoft), Graphs (Jgraph by RogueWave) and others. Such encapsulation is the equivalent of the mime-type mechanism used on the web today. Web implementation of mime limits the user to presentation of pre-existing files. Template adapters, on the other hand, provide a mechanism for on-the-fly creation of files according to that mime type.
Data-Centric Navigation
The end user’s access to HyperRelational systems is still done through the use of a browser metaphor. By pointing to a site and performing simple navigation, users can get ubiquitous access to relevant information. Navigating is accomplished through the use of two gestures: point-and-click and drag-and-drop, which provides an enhancement over the web’s point-and-click metaphor for text-centric navigation. Instead of using text and text-centric elements, HyperRelational systems allow the user to interact and navigate through data and data-centric elements. As such, data-centric systems can be navigated more naturally, and much more simply, through this metaphor than the current web metaphor.
MetaData-Based Navigation Protocol
The underlying protocol in HyperRelational systems is HRNP (HyperRelational Navigation Protocol), a meta-data naming protocol. It provides a mechanism for encapsulating meta-data behind the data it represents, all contained within the URL of the link. These meta-data links have been named Meta-Links.
HRNP also allows multiple links to be combined in a way that represents piping of one or more components into a target component. Such Meta-Links are created on the fly, and their combinations are translated into replies, which users receive, view, and interact with next. This is similar to the role hyperlinks play in the hypertext world. However, hyperlinks are static by nature, always leading to the same result, and they do not give users the flexibility to combine or alter their direction. This limitation is also portrayed by the nature of HTTP, which is merely a transfer protocol for receiving files and sending requests to forms.
Scalability
Due to the benefits it provides, HyperRelational Navigation is usually layered on top of large database systems as well as a large number of users. The scalability of a HyperRelational solution is essential for its practicality. It can be measured along three independent axes, which we will examine in the following sections:
Number of Objects/Object Models
As the enterprise deploys HyperRelational systems across various aspects of the corporation, it can choose two methods of scaling up in size: a single large model or multiple correlated small models. Building a single large model is well suited to applications that are tightly integrated, like ERP applications. Such applications may be converted into a HyperRelational system in a number of steps, addressing more objects from the model at every step. This creates a HyperRelational system that spans over a very large number of objects.
Other homegrown models usually tend to be partial solutions covering a single aspect of the business. An enterprise should, in that case, start building a HyperRelational system on top of one of those solutions, then bring in more models over time, correlating them to create an enterprise-wide system that contains a large number of correlated models.
In both cases, the end user should not feel the difference as the number of objects/models increases. The latency users perceive when navigating from one object to another, or from one model to another, should remain constantly small as additional objects and models are incorporated. By separating the representations of inter-entity relationships from the entities themselves, HyperRelational systems provide immediate and random access to any required relation, providing immediate response to any user request.
Number of Users
As the enterprise starts deploying HyperRelational systems, more users can tap into such solutions. A HyperRelational solution must allow for growth in usage, without any negative impact to the perceived performance of the system. In order to support such a requirement, HyperRelational systems should enable the enterprise to scale the number of HyperRelational servers and load-balance the requests among those servers. This is similar in nature to the way a web-based solution is scaled when the number of hits grows. Servers for highly used models scale up faster, while sparsely used models can meet the needs of the organization through a small number of servers.
In any situation, this can be done at the server layer, without any perceived change in the user’s experience. The HyperRelational layer, in the middle tier of the system, should never become the performance bottleneck for the enterprise. Another benefit from using a HyperRelational system is a smaller load on the storage tier as well. This is due to the reduction in the number of required hits (separate queries) on the database when reaching a resolution to a situation.
Number of Records
Because the use of HyperRelational systems is mainly in the enterprise, we see databases where tables are very heavily populated with large sets of records. In any stage of development or deployment, HyperRelational performance will not be impaired by a growing number of records, beyond the minimal performance hit on the underlying database. A HyperRelational system must only be based on meta-data, so it does not require special links inside the records—or relationships that are inferred from the data itself.
The ultimate test for the scalability of HyperRelational systems is their deployment on top of enterprise-wide applications within the largest corporations. The first large-scale commercial HyperRelational solution—Baan Data Navigator—and its link to several mid-size applications, such as Aurum and Scopus, supports and proves all three models of scalability discussed above.
Deployment
Deployment of HyperRelational systems requires no changes in underlying IT infrastructure. It works with existing standards in data storage, such as SQL databases and ODBC drivers. In the future, it will work with OLE-DB and its upcoming flavors, such as OLE-DB for OLAP.
HyperRelational systems, by their nature, are very meta-data driven. Consequently, these systems leverage existing investments in meta-data repositories and tools. For proprietary meta-data repositories, HyperRelational tools enable the enterprise to define its own sources for meta-data. Those repositories are collected into the HyperRelational repository and combine with other sources of meta-data to define a comprehensive enterprise relationship model. The resulting systems can be deployed on top of any TCP/IP—based networks for Intranet, Extranet, or even Internet usage. Because HyperRelational systems are using web clients as the user environment, deployment on individual desktops is as simple as ensuring that users have a browser. Overall, HyperRelational systems can fully leverage the existing infrastructure investment an enterprise has put in place.
The nature of the HyperRelational navigation metaphor can be used with a variety of scenarios. In general, these systems help resolve situations, or they provide assistance in making both tactical and strategic business decisions. Tactical decisions usually depend on atomic transactional data, and they resolve a situation that manifests itself in the micro level of operations. On the strategic side, data usually comes from looking at the macro level through aggregate data from analytic data warehouse/marts. The HyperRelational navigation is the first approach to enable a user to seamlessly connect and view both stores as if they were completely unified, without losing the individual benefits of each model.
Due to the distributed nature of HyperRelational systems, the deployment model allows the installation of systems to be server-centric. A system is installed and updated at a single point, yet deployment occurs at each and every desk that is connected to it over the network. This lowers the cost of managing and maintaining such enterprise systems. It provides an organization with a single point of control over the information that it opens to its clients, inside and outside the enterprise boundaries.
Finally, the whole process of taking an existing relational system and layering a HyperRelational solution on top of it is almost automatic. This lowers the cost of creation and ownership dramatically, and it enables the enterprise to benefit from the value created immediately. These two factors combine to create a very high and immediate return on investment.
Seven Rules of HyperRelational Navigation
Only systems that support of the following seven rules can claim to be HyperRelational. These rules govern aspects of development, deployment, and usage.
Any-to-Any Relationships
The cornerstone of the HyperRelational navigation metaphor is the ability of the end user to combine any two elements using the inherent relationship between them. In order to support this metaphor, an any-to-any relationship must exist throughout the underlying object model the user is navigating. This any-to-any relationship may also have multiple paths among members, which the user can traverse in accordance with the situation at hand. As the number of relations grows exponentially with the number of objects in the model, the any-to-any map must be completed automatically, or it is not practical for mid- to large-scale models.
Drag and Relate Interaction Metaphor
HyperRelational navigation is expressed through the use of a drag-and-relate metaphor. In this metaphor, users can combine meta-data descriptors of source and target components to create a single HyperRelational statement. This is currently the only gesture enabling users to perform such concatenation in a simple and modeless fashion. Other attempts to manifest the user interface in this way either grow too cumbersome, become too difficult for the user to understand, or do not scale well to large numbers of objects/models.
Point of View Navigation
HyperRelational systems provide their users with an experience called point-of-view navigation. That phrase represents the user’s ability to view a large multi-faceted body of information, continually looking at it from a different point of view. Provided with this interactive lens, the user is empowered to decide, ad hoc, what the next point of view will be—and the angle by which they will view the information at hand. While predetermined or recommended paths through the information may exist and presented on screen, the user is not limited to travel within the boundaries of those paths.
Meta-Links
Users navigate through the HyperRelational environment using browsers and links. The web’s nomenclature for links applies in this environment also; they are highlighted by a color and underlined. However, HyperRelational links do not contain a path to the next page of information. They only contain meta-data descriptors as to the nature of the link. Users combine these meta-data descriptors in order to create a link during run-time. These user-created links are called Meta-Links. No mechanism that contains predetermined links can provide comparable capabilities, due to the deterministic nature of the link that describes only a navigation target within the link.
Three-Way Scalability
As enterprises require a high level of scalability from its systems, HyperRelational systems provide and support scalability along every required dimension: Objects, Users, and Records. The fundamental requirement is for the system to respond within a constant time to a request, no matter how many objects or object models it is spanning. This means developing a mechanism that will keep the response time constant as the number of users grows—by scaling the number of concurrent servers. The system must not be dependent on information stored in the data itself, in order to prevent a slowdown as the database it is layered above grows.
Integration of Different Data Sources and Different Data Stores
Every HyperRelational Server in the enterprise can map to a different data source. Each of those sources is mapped into an object model, and those object models are correlated to a combined enterprise object model. This establishes a predictable way for the enterprise to correlate different sources of information running over multiple types of data stores. Such multi-model solution provides a seamless client layer on top of legacy, C/S, Analytical, Warehouse, and O/R stores.
Confederated Components Model
As described earlier, HyperRelational systems deploy a confederated component model. The rules of this model are essential to enable a HyperRelational system to grow and extend its users and usage over time. The confederation requires that every component the user sees will be fully encapsulated, which means it knows how to be uniquely represented, perform its display, maintain persistent storage, and dispose of itself. Through drag-and-relate actions, every component can interact with every component of a compatible class to create a Meta-Link and provide the user with an answer. Components must inherit the operating environment context while performing all user interactions. Finally, users can share components that they or others have created and subclass those components to create others.
When two sets of confederated components are combined, the result is a single confederation of all components contained in the union of its two creators, rather than two confederations. If that last rule is broken, HyperRelational solutions cannot grow seamlessly for the end user, which breaks the primary benefit of HyperRelational systems—integration.
Summary
HyperRelational systems built on confederated component models provide integration, navigation and simplification of disparate data sources for improving organizational speed and responsiveness resulting in improved efficiency for the enterprise network. HyperRelational navigation enables the user to navigate and dynamically interact with multiple corporate information sources. HyperRelational systems leverage and extend the Web’s Hypertext-based metaphor to give everyone in the organization easy, fast, efficient access to information contained within ERP systems, legacy databases, simple file systems, HTML documents, and other data sources.